![]()
The Librarians of the Future Will Be AI Archivists It isn’t easy to archive images. That’s where AI comes in. BY COURTNEY LINDER MAY 13, 2020
Un científico informático de la Biblioteca del Congreso está utilizando el aprendizaje automático para aislar imágenes históricas de archivos de periódicos digitales. El proyecto, llamado Newspaper Navigator, utiliza algoritmos ópticos de reconocimiento de caracteres para convertir caracteres escritos a mano o basados en texto en un documento de búsqueda. El aprendizaje automático automatiza el proceso.
En julio de 1848, L’illustration, un semanario francés, imprimió la primera foto que apareció junto a una historia. Representaba las barricadas parisinas levantadas durante el levantamiento de los días de junio de la ciudad. Casi dos siglos después, el fotoperiodismo ha proporcionado a las bibliotecas millones imágenes de archivo que cuentan historias de nuestro pasado. Pero sin un enfoque metódico para curarlas, estas imágenes históricas podrían perderse en montones interminables de datos.
Es por ello que la Biblioteca del Congreso en Washington, DC está experimentando un proyecto sobre esta cuestión. Los investigadores están utilizando algoritmos especializados para extraer imágenes históricas de los periódicos. Si bien los escaneos digitales ya pueden compilar fotos, estos algoritmos también pueden analizarlas, catalogarlas y archivarlas. Esto dio como resultado 16 millones de páginas de periódicos en imágenes que los archiveros pueden visualizar con una simple búsqueda.
Ben Lee, en la Biblioteca del Congreso especialista en computación en la Universidad de Washington, encabeza lo que se llama Newspaper Navigator. Su conjunto de datos proviene de un proyecto existente llamado Chronicling America, que compila páginas de periódicos digitales entre 1789 y 1963.
Se dio cuenta de que la biblioteca ya se había embarcado en un viaje de crowdsourcing para convertir algunas de esas páginas de periódicos en una base de datos de búsqueda, con un enfoque en el contenido relacionado con la Primera Guerra Mundial. Los voluntarios podrían marcar y transcribir las páginas de periódicos digitales, algo que las computadoras no son capaces de hacer de una manera adecuada. En efecto, lo que habían construido era un conjunto perfecto de datos de entrenamiento para un algoritmo de aprendizaje automático que podía automatizar todo ese trabajo agotador y laborioso.
Newspaper Navigator se basa en la misma tecnología que los ingenieros utilizaron para crear Google Books. Se llama reconocimiento óptico de caracteres u OCR para abreviar, y es una clase de algoritmos de aprendizaje automático que pueden traducir imágenes de símbolos escritos a mano o escritos, como palabras en una página de revista escaneada, en texto digital legible por máquina. Pero las imágenes son algo completamente distinto.
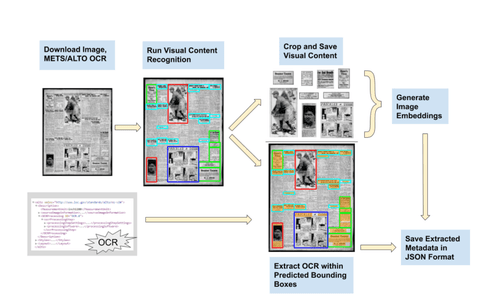
Utilizando el aprendizaje profundo, Lee creó un modelo de detección de objetos que podría aislar siete tipos diferentes de contenido: fotografías, ilustraciones, mapas, cómics, dibujos animados editoriales, titulares y anuncios. Lee también dice que, incluso a pesar de sus mejores esfuerzos, este tipo de sistemas siempre codificará algún sesgo humano. «Es fácil suponer que el aprendizaje automático resuelve todos los problemas, eso es una fantasía, pero en este proyecto, creo que es una oportunidad real para enfatizar que debemos tener cuidado de cómo usamos estas herramientas».















{kind=link}