En las últimas dos décadas, los espacios compartidos de trabajo y producción, como los Fablabs, han ganado relevancia en contextos urbanos, atrayendo la atención de responsables políticos y académicos de la geografía económica y los estudios urbanos. Los Fablabs son talleres abiertos que fomentan la innovación desde las bases mediante el acceso compartido a máquinas de fabricación digital y la posibilidad de colaborar y compartir conocimiento, tanto presencialmente como en línea. Los usuarios de estos espacios, conocidos como «Makers», son presentados como precursores de la democratización de la producción y como actores clave en la transformación de las economías urbanas en la era del capitalismo digital.
El libro, basado en una investigación doctoral centrada en los Makers y los Fablabs en Turín, utiliza la observación etnográfica en Fablab Torino para ofrecer un marco teórico original. Este combina la geografía económica post-estructuralista con conceptos de la Teoría del Actor-Red y los Estudios de Ciencia y Tecnología. Con un enfoque interdisciplinario, el análisis examina cómo el «Making» se configura como una nueva forma de trabajo y producción a través de tres conceptos clave: conocimiento, materialidad y trabajo.
La investigación destaca cómo los Fablabs y la escena Maker en Turín se constituyen performativamente mediante la interacción entre teorías económicas y arreglos socio-técnicos diseñados para materializar dichas teorías. La relevancia geográfica del fenómeno no reside en configuraciones espaciales estáticas, sino en las espacialidades heterogéneas y emergentes generadas por las prácticas individuales y las dinámicas sociomateriales que estructuran organizaciones económicas como los Fablabs.
Este estudio resulta de interés para académicos de ciencias sociales que investigan la reconfiguración del trabajo, la producción en las ciudades y las transformaciones económicas mediadas digitalmente.
Se analiza el impacto de Dialnet Métricas en la evaluación de la producción científica en Biblioteconomía y Documentación, destacando cómo combina métricas tradicionales y datos alternativos, como visualizaciones y recomendaciones. Además, se examinan las revistas de mayor impacto y los autores más citados en el campo, proporcionando una herramienta clave para medir la influencia académica en revistas en español.
Dialnet ha calculado las citas emitidas por 600 revistas en los últimos 5 años, considerando un total de 59.725 citas. Se incluyeron revistas internacionales para completar la cobertura global. La tasa de autorreferenciación es de 0,16, y el índice de coautoría en el ámbito de Documentación es de 1,9. A continuación, se presenta una tabla con las revistas más destacadas según su índice de impacto:
Revistas con mayor impacto en Dialnet Métricas 2023
La tabla muestra un conjunto de 24 revistas académicas destacadas en el campo de la documentación, clasificados según su índice de impacto en los últimos 5 años. Este índice refleja la relevancia y el reconocimiento de cada revista dentro de la comunidad académica, medido a través del número de citas recibidas y artículos publicados.
Índice de coautoría y tasa de autorreferenciación: El índice de coautoría en el campo de Documentación es de 1,9, lo que indica una colaboración significativa entre autores en estas revistas. Además, la tasa de autorreferenciación es baja (0,16), lo que sugiere que las revistas citan fuentes externas en lugar de autorreferirse excesivamente, lo cual es un signo positivo para la diversidad y calidad de las publicaciones.
Revistas de alto impacto: Las revistas más destacadas en la tabla son El profesional de la información (con un impacto de 2,75), seguida por Revista española de documentación científica (0,94) y Revista general de información y documentación (0,60). Estas revistas tienen un alto número de citas, lo que indica que son fuentes clave en el campo de la documentación.
Revistas especializadas: Otras publicaciones, como Anuario ThinkEPI (0,52) y Hipertext.net (0,48), aunque con un impacto ligeramente menor, siguen siendo relevantes y ofrecen contribuciones importantes, especialmente en temas de documentación digital y comunicación interactiva.
Revistas con menor impacto: Al final de la lista, encontramos revistas con un impacto de casi nulo, como Anuari de l’Observatori de Biblioteques, Llibres i Lectura y Mi biblioteca, que tienen un índice de impacto menor a 0,01. Esto podría deberse a un menor volumen de citas y a una cobertura más local o específica.
Diversidad en la cobertura: La tabla muestra una diversidad de enfoques, desde revistas más generales de biblioteconomía y documentación hasta publicaciones especializadas en áreas como patrimonio documental, sistemas de información y archivo. Esto refleja la variedad de temas que abarca el campo de la documentación.
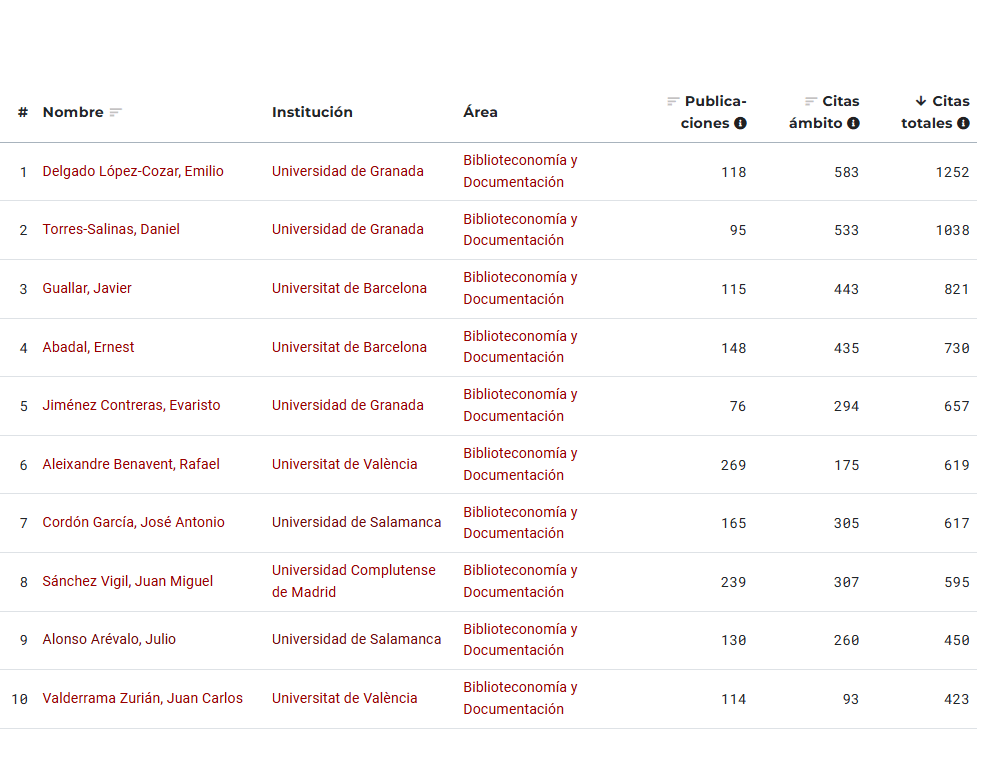
investigadores más citados en el ámbito de la Biblioteconomía y Documentación:
La tabla presenta un listado de investigadores clasificados por el número total de citas recibidas en publicaciones dentro del ámbito de la biblioteconomía y documentación. Además, se muestran las citas totales, las citas en el ámbito específico, y algunos índices como el Índice H y el Índice H5, que reflejan la productividad y el impacto de sus publicaciones a lo largo del tiempo.
Tabla de investigadores más citados:
Autores más citados en Biblioteconomía Documentación 2023
Estos 10 investigadores representan a las instituciones académicas más relevantes en el campo de la biblioteconomía y la documentación en España. La Universidad de Granada y la Universitat de Barcelona destacan como dos de las principales fuentes de investigación en este ámbito. Los altos índices de citas de estos investigadores demuestran no solo su producción académica, sino también la relevancia y el impacto de sus estudios dentro de la disciplina. Sin duda, sus trabajos han contribuido significativamente al avance del conocimiento en biblioteconomía y documentación, y siguen siendo fundamentales para las futuras investigaciones en este campo.
Emilio Delgado López-Cozar (Universidad de Granada):
Citas en ámbito: 583 Citas totales: 1252
Emilio Delgado López-Cózar es un destacado académico español en Biblioteconomía y Documentación, Catedrático en la Universidad de Granada. Su investigación se centra en la evaluación de la ciencia, la metodología de la investigación y las métricas científicas. Ha desarrollado sistemas para medir el rendimiento de revistas y científicos, y es conocido por su análisis de métricas alternativas. Su impacto académico es significativo, con miles de citas y un alto índice h.
Daniel Torres-Salinas (Universidad de Granada):
Citas en ámbito: 533 Citas totales: 1038
Daniel Torres-Salinas es un destacado académico de la Universidad de Granada, especializado en Biblioteconomía y Documentación, con enfoque en evaluación de la ciencia y Bibliometría. Su investigación abarca la evaluación de la investigación universitaria, libros científicos y nuevas métricas, con un impacto significativo reflejado en sus numerosas citas y publicaciones en revistas de prestigio.
Javier Guallar (Universitat de Barcelona):
Citas en ámbito: 443 Citas totales: 821
Javier Guallar. Es profesor e investigador en la Facultad de Información y Medios Audiovisuales de la Universidad de Barcelona, doctor en Información y Documentación por la UB y en Comunicación por la UPF. Especializado en curación de contenidos, es autor de libros y artículos sobre el tema, editor de colecciones académicas, y fue subdirector de la revista «El Profesional de la Información». También es conocido por su trabajo en evaluación de revistas científicas y por desarrollar el sistema de curación de contenidos de las 4S’s
Ernest Abadal (Universitat de Barcelona):
Citas en ámbito: 435 Citas totales: 730
Ernest Abadal es Catedrático de la Facultad de Información y Medios Audiovisuales de la Universitat de Barcelona y actualmente Vicerrector Adjunto al Rector y de PDI. Doctor en Ciencias de la Información, su investigación se centra en el acceso abierto, la ciencia abierta y las publicaciones digitales. Ha dirigido proyectos de investigación sobre acceso abierto a la ciencia en España y es coordinador del Grupo de Investigación Consolidado «Cultura y contenidos digitales». Es autor de numerosas publicaciones y ha ocupado diversos cargos académicos y de gestión en la UB.
Evaristo Jiménez Contreras (Universidad de Granada):
Citas en ámbito: 294 Citas totales: 657
Evaristo Jiménez Contreras es Catedrático de Bibliometría en la Universidad de Granada y miembro del grupo de investigación EC3. Su trayectoria se centra en la evaluación de la ciencia, bibliometría y comunicación científica. Ha dirigido numerosas tesis doctorales sobre análisis bibliométricos en diversas disciplinas. Es autor de publicaciones influyentes sobre la evolución de la actividad investigadora en España y el impacto de las políticas de evaluación.
Rafael Aleixandre Benavent (Universitat de València):
Citas en ámbito: 175 Citas totales: 619
Rafael Aleixandre Benavent es investigador vinculado al Consejo Superior de Investigaciones Científicas (CSIC) y a la Universidad de Valencia. Su trabajo se centra en bibliometría, informetría, cienciometría y evaluación de la investigación. Es autor de numerosas publicaciones sobre comunicación científica, análisis bibliométricos y evaluación del impacto científico
José Antonio Cordón García (Universidad de Salamanca):
Citas en ámbito: 305 Citas totales: 617
José Antonio Cordón García es Catedrático de la Universidad de Salamanca, especializado en Biblioteconomía y Documentación. Su investigación se centra en fuentes de información, industria editorial, historia del libro y lectura digital. Dirige el Grupo de Investigación E-LECTRA y el Máster en Patrimonio Textual y Humanidades Digitales. Ha recibido el Premio Nacional de Investigación 2012 en Edición y Sociedad del Conocimiento, y ha publicado extensamente sobre edición y lectura digital
Juan Miguel Sánchez Vigil (Universidad Complutense de Madrid):
Citas en ámbito: 307 Citas totales: 595
Juan Miguel Sánchez Vigil es Catedrático de la Universidad Complutense de Madrid, especializado en Documentación Fotográfica y Editorial. Doctor en Ciencias de la Información, Historia del Arte y Geografía e Historia, ha ocupado cargos de gestión académica. Su investigación se centra en fotografía, edición y documentación, con numerosas publicaciones y dirección de tesis doctorales. Es editor, fotógrafo y documentalista gráfico, y ha recibido reconocimientos por su labor en el campo de la edición y la sociedad del conocimiento.
Julio Alonso Arévalo (Universidad de Salamanca):
Citas en ámbito: 260 Citas totales: 450
Julio Alonso Arévalo es bibliotecario responsable de la Biblioteca de Traducción y Documentación de la Universidad de Salamanca. Licenciado en Geografía e Historia, es experto en acceso abierto y edición digital. Es editor del repositorio E-LIS, coordinador de la lista InfoDoc y creador del blog «Universo abierto». Ha publicado sobre e-books, gestión del conocimiento y nuevas tecnologías en bibliotecas, recibiendo el Premio Nacional de Investigación en Edición y Sociedad de la Información en España en 2013.
Juan Carlos Valderrama Zurián (Universitat de València):
Citas en ámbito: 93 Citas totales: 423
Juan Carlos Valderrama Zurián es Doctor en Medicina y Profesor Titular de la Facultad de Medicina en la Universitat de València. Su investigación se centra en drogodependencias, gestión del conocimiento y estudios epidemiológicos, con énfasis en población inmigrante, abuso de esteroides y prevención de VIH/VHC. Ha publicado numerosos artículos en revistas nacionales e internacionales sobre adicciones y bibliometría. Actualmente lidera el proyecto DATAUSE UV, enfocado en la gestión y transferencia del conocimiento emergente.
MANUEL HERNÁNDEZ LEAL «Manifestación por la poesía. La biblioteca como motor de cambio en su entorno» JORNADA TRANSFRONTERIZA #coopera “Bibliotecas en Comunidad”/ “As Bibliotecas na Comunidade”
Manuel Hernández Leal explicó el alcance de cómo estas instituciones permiten el cambio al promover la participación y la inclusión, a través de una iniciativa ciudadana que denominó “Manifestación por la poesía”.
Manuel, bibliotecario de la biblioteca Pública de Villamayor (Salamanca) destaca la importancia de que los bibliotecarios se adapten al entorno para hacer que las bibliotecas sean útiles y atractivas, convirtiéndolas en lugares que inviten a soñar y que la comunidad sienta como propios. Afirma que las bibliotecas son espacios divertidos y resalta actividades como «poner el libro en escena», «vestir la biblioteca» o «galletas para perros». Su trabajo en Villamayor es un ejemplo de compromiso y dedicación que inspira en otros municipios.
Videoconferencia. LAS BIBLIOTECAS SON LAS PERSONAS: LA IMPORTANCIA DEL ESPACIO COMO SERVICIO Y ESTRATEGIA por Julio Alonso Arévalo
La transformación de los espacios bibliotecarios en lugares estratégicos y flexibles fue otro punto destacado. Julio Alonso Arévalo subrayó el valor del espacio en las bibliotecas como generador de comunidad y conector entre las personas El espacio en las bibliotecas se ha convertido en un servicio estratégico que va más allá de albergar libros, transformándose en un entorno flexible y accesible para diversos fines. Al ofrecer áreas dedicadas a la lectura, el estudio, el trabajo colaborativo o la creatividad, las bibliotecas responden a las necesidades cambiantes de sus usuarios. Este enfoque promueve la interacción social, el aprendizaje comunitario y el bienestar emocional.
El valor del espacio en una biblioteca no radica solo en su colección de libros, sino en su capacidad para generar comunidad. En una época marcada por la digitalización, el espacio físico de la biblioteca sigue siendo insustituible. Es un lugar para aprender, colaborar, reflexionar y descansar. Los usuarios encuentran en ella una atmósfera única que fomenta el intercambio de ideas, el estudio y la creatividad. Además, las bibliotecas desempeñan un papel crucial en barrios y comunidades al convertirse en puntos de encuentro. Son escenarios donde las diferencias culturales se diluyen frente a un objetivo común: la construcción colectiva del conocimiento y la cultura. Al final, más que edificios, las bibliotecas son nodos vivos de inclusión y transformación social.
Gemma Conroy, «How ChatGPT and Other AI Tools Could Disrupt Scientific Publishing», Nature 622, n.o 7982 (10 de octubre de 2023): 234-36, https://doi.org/10.1038/d41586-023-03144-w.
La inteligencia artificial generativa tiene el potencial de transformar profundamente la publicación científica, pero su integración debe gestionarse cuidadosamente. Solo a través de un enfoque responsable y ético será posible maximizar sus beneficios mientras se mitigan los riesgos asociados.
Las herramientas de inteligencia artificial generativa, como ChatGPT, están revolucionando la publicación científica al transformar la forma en que se redactan y revisan manuscritos, informes de revisión por pares y solicitudes de subvenciones. Estas herramientas ofrecen beneficios significativos, como mayor eficiencia y equidad, pero también plantean preocupaciones relacionadas con la precisión, la ética y la calidad de las publicaciones. Por ejemplo, investigadores no nativos en inglés pueden superar barreras lingüísticas con la ayuda de estas tecnologías, mientras que el tiempo necesario para redactar documentos se reduce considerablemente. Sin embargo, estas mismas herramientas presentan riesgos asociados a inexactitudes y posibles usos indebidos.
Uno de los mayores cambios que trae la inteligencia artificial es la posible transformación del formato de los artículos científicos. En el futuro, los artículos podrían presentarse como documentos interactivos que permiten al lector explorar los datos y resultados de manera personalizada, en lugar de depender de los formatos estáticos actuales. Asimismo, la IA podría facilitar la realización de meta-análisis más amplios y detallados al procesar grandes volúmenes de literatura científica, algo que excede las capacidades humanas tradicionales. Esto abriría nuevas posibilidades para descubrir patrones y tendencias en la investigación.
No obstante, el uso de herramientas de IA generativa no está exento de riesgos. Estas tecnologías, al basarse en patrones más que en la verificación de hechos, pueden generar errores, referencias falsas o incluso artículos fraudulentos. Además, su accesibilidad podría fomentar prácticas poco éticas, como la proliferación de “fábricas de artículos”, donde se crean y venden manuscritos o posiciones de autoría. Por otro lado, las herramientas actuales para detectar textos generados por IA no son lo suficientemente fiables, lo que dificulta la identificación de fraudes y plantea un desafío significativo para los editores y revisores.
En el ámbito ético, el desarrollo de estas tecnologías también genera preocupaciones sobre plagio y derechos de autor. Muchos modelos de IA se entrenan con datos recopilados de Internet sin garantizar el consentimiento ni respetar restricciones de uso, lo que ha llevado a críticas que describen a la IA generativa como “plagio automatizado”. Además, las preocupaciones sobre la confidencialidad en la revisión por pares han llevado a algunas instituciones a prohibir el uso de estas herramientas en procesos sensibles como la evaluación de becas.
La equidad es otro aspecto clave. Mientras que herramientas como ChatGPT podrían nivelar el campo de juego para investigadores que no hablan inglés como lengua nativa, la posible monetización de estas tecnologías podría limitar su acceso a científicos de instituciones con menos recursos. Esto podría agravar las desigualdades ya existentes en la academia, especialmente si las herramientas avanzadas se vuelven prohibitivamente caras.
Para abordar estos desafíos, es esencial equilibrar la innovación con la integridad. Las revistas científicas deben establecer directrices claras sobre el uso de la IA, mientras que los gobiernos y las instituciones deben regular su implementación para garantizar una adopción ética y equitativa. Por su parte, los investigadores deben mantener habilidades críticas en redacción y análisis para no depender exclusivamente de estas herramientas en un entorno académico en rápida evolución.
Resolución de 9 de diciembre de 2024, de la Comisión Nacional Evaluadora de la Actividad Investigadora, por la que se publican los criterios para la evaluación de la actividad investigadora.
La Comisión Nacional Evaluadora de la Actividad Investigadora (CNEAI) ha aprobado los criterios para la evaluación de la actividad investigadora correspondientes a la convocatoria de 2024. Estos criterios, que serán publicados en el Boletín Oficial del Estado (BOE), ya se han difundido para facilitar la preparación anticipada de las solicitudes. Finalmente, para garantizar transparencia y uniformidad, ANECA ha publicado un baremo único que será aplicado por los quince Comités Asesores.
Entre los cambios destacados, se elimina el apartado de «mínimos orientativos», permitiendo la obtención de una evaluación positiva mediante cinco aportaciones que cumplan con los criterios generales, sin depender de indicadores cuantitativos relacionados con medios de difusión. Esto refuerza el enfoque en la calidad intrínseca de las aportaciones.
El baremo para la evaluación de la actividad investigadora en la convocatoria de 2024 de los sexenios de investigación establece criterios clave para calificar las aportaciones de los solicitantes, otorgando mayor peso al impacto científico y contemplando elementos relacionados con la originalidad, la relevancia social y la promoción de la ciencia abierta. A continuación, se resumen los principales aspectos de cada criterio:
Contribución al progreso del conocimiento (10%)
Este apartado evalúa la originalidad, innovación y pertinencia de la investigación, destacando la capacidad del trabajo para abordar problemas relevantes en el área y proponer soluciones novedosas. Se valora también el enfoque metodológico, incluyendo el desarrollo de nuevos métodos o la mejora de los existentes. Se excluyen trabajos meramente descriptivos, recopilaciones bibliográficas sin análisis crítico o traducciones sin aportaciones significativas.
Impacto científico (60%)
Es el criterio más relevante, dividido en cuatro subcategorías principales:
Uso de la aportación: Se mide por lecturas, descargas y visualizaciones en plataformas académicas.
Citas recibidas: Considera el número y calidad de las citas recibidas, excluyendo autocitas.
Calidad del medio de difusión: Se analiza la reputación del medio donde se publica, incluyendo revisiones por pares y estándares de calidad.
Impacto del medio: Examina el reconocimiento científico del medio de publicación, con énfasis en premios, críticas y reseñas.
Se tienen en cuenta otros indicadores como vínculos con proyectos de investigación, tesis doctorales, premios y menciones en medios especializados.
Impacto social (10%)
Evalúa la repercusión de las investigaciones fuera del ámbito académico, como su influencia en políticas públicas, documentos normativos, guías clínicas o la industria. Además, se considera su difusión en medios de comunicación, plataformas digitales y eventos culturales, y la interacción con el público.
Contribución a la ciencia abierta (10%)
Se premian aportaciones accesibles públicamente, ya sea en versiones finales o preliminares, y el cumplimiento de principios FAIR en datasets y software. También se valora la publicación en revistas de acceso abierto (diamante) y el uso de licencias libres como Creative Commons.
Aportación preferente (10%)
Se analiza el ajuste de las aportaciones al tipo preferente definido en los criterios de evaluación, como artículos, libros, capítulos de libro, patentes o contribuciones a congresos.
Circunstancias reductoras
La puntuación puede reducirse en casos como:
Reiteración de publicaciones: Más de tres aportaciones en un mismo medio sin justificación suficiente.
Conflicto de interés editorial: Relaciones que comprometan la objetividad del proceso editorial.
Malas prácticas: Plagio, duplicación de contenido, alteración de datos o artículos retractados.
Procesos de revisión cuestionables: Medios con estándares poco fiables o periodos de aceptación injustificadamente cortos.
Autoría insuficientemente justificada: Participación no justificada adecuadamente en casos de coautoría múltiple.
Este baremo asegura una evaluación integral y motivada de las contribuciones, exigiendo evidencia clara de su relevancia científica, metodológica y social, y fomentando la transparencia en la producción académica.
Con el aumento de la popularidad de la inteligencia artificial generativa (IA), varios editores académicos han establecido acuerdos con empresas tecnológicas que buscan utilizar contenido académico para entrenar los grandes modelos de lenguaje (LLMs) que sustentan sus herramientas de IA. Estos acuerdos han resultado altamente lucrativos, generando millones de dólares para los editores involucrados.
Roger Schonfeld, co-creador de un nuevo rastreador de acuerdos y vicepresidente de bibliotecas, comunicación académica y museos en Ithaka S+R, una firma de consultoría en educación superior con sede en Nueva York, comenta: “Estábamos observando anuncios de estos acuerdos y comenzamos a pensar que esto está empezando a convertirse en un patrón”. Schonfeld y su equipo lanzaron en octubreGenerative AI Licensing Agreement Tracker, una herramienta destinada a recoger los acuerdos que se están realizando entre editores y compañías de tecnología.
El rastreador tiene como objetivo no solo documentar cada acuerdo individual, sino también identificar y analizar las tendencias generales que emergen de estos acuerdos. Al proporcionar una fuente centralizada de información, el tracker facilita que la comunidad académica y tecnológica comprendan mejor cómo se está utilizando el contenido académico para el desarrollo de IA generativa.
Este fenómeno refleja una creciente intersección entre la publicación académica y el desarrollo de tecnologías avanzadas de IA. Los editores, al vender derechos de uso de sus artículos para entrenar modelos de lenguaje, están aprovechando nuevas oportunidades de ingresos, mientras que las empresas de tecnología aseguran el acceso a vastas cantidades de datos necesarios para mejorar la precisión y capacidad de sus sistemas de IA.
El seguimiento de estos acuerdos es crucial para mantener la transparencia en cómo se utiliza el contenido académico y para asegurar que se respeten los derechos de los autores y las instituciones educativas. Además, este rastreador puede ayudar a identificar posibles implicaciones éticas y legales relacionadas con el uso de investigaciones académicas en el entrenamiento de inteligencias artificiales.
Principales acuerdos:
Taylor & Francis firmó un acuerdo de 10 millones de dólares con Microsoft
Wiley generó 23 millones de dólares en un acuerdo con una empresa no revelada y espera otros 21 millones este año.
Otros grandes editores, como Elsevier y Springer Nature, no han comentado sobre acuerdos similares.
También los editores están creando nuevas posiciones y programas, como el «Wiley AI Partnerships», para formalizar colaboraciones con empresas de tecnología. Esto refleja que estos acuerdos no son excepcionales, sino parte de una estrategia a largo plazo.
Los acuerdos entre editores académicos y empresas de IA están transformando la publicación científica, generando ingresos sustanciales y redefiniendo la relación entre autores, editores y tecnología. Sin embargo, el debate sobre la transparencia y las implicaciones éticas de estas prácticas sigue abierto.
Algunos académicos han mostrado preocupación por el uso de su contenido sin su conocimiento.
De Gruyter Brill creó una página informativa para explicar los acuerdos y abordar las inquietudes de los autores.
Cambridge University Press & Assessment adoptó un enfoque de participación voluntaria, contactando a 20.000 autores para obtener su consentimiento explícito.
Comas-Forgas, Ruben, Alexandros Koulouris, y Dimitris Kouis. s. f. «‘AI-Navigating’ or ‘AI-Sinking’? An Analysis of Verbs in Research Articles Titles Suspicious of Containing AI-Generated/Assisted Content». Learned Publishing n/a (n/a): e1647. https://doi.org/10.1002/leap.1647.
La misinformation (en español, desinformación) se refiere a la difusión de información falsa o inexacta, pero sin la intención deliberada de engañar. Esto la distingue de la disinformation (desinformación intencional), que es información falsa creada y difundida con el propósito de manipular, confundir o influir de manera premeditada.
El artículo aborda cómo los rumores y las interpretaciones erróneas tienen un impacto fundamental en la difusión de desinformación, especialmente en el contexto de las elecciones en EE. UU. Según los autores, el problema no radica únicamente en la presencia de hechos falsos, sino en los marcos mentales que las personas emplean para interpretar la información. Estos marcos influyen en la manera en que se entienden los eventos, lo que a menudo deriva en rumores y malentendidos.
Los rumores son un intento colectivo de dar sentido a situaciones inciertas. Si bien muchas veces son falsos, reflejan confusiones o temores reales dentro de las comunidades. En contraste, la desinformación implica una manipulación intencionada de estos procesos, mediante la introducción de pruebas falsas o la distorsión de los marcos que las personas utilizan para interpretar los hechos.
La relación entre los marcos y la evidencia es clave. Los marcos mentales no solo guían cómo las personas seleccionan y analizan la evidencia, sino que también pueden ser moldeados intencionalmente por medios, líderes políticos y comunidades. Por ejemplo, durante las elecciones de 2020, el marco del «fraude electoral» promovido por Donald Trump llevó a muchos a interpretar el uso de bolígrafos Sharpie en Arizona como evidencia de un intento de manipulación, lo que dio lugar al llamado Sharpiegate.
El artículo también resalta el papel de las redes sociales en estos procesos. Las plataformas digitales amplifican contenidos que se alinean con marcos políticos dominantes, favoreciendo la viralización de rumores. Los influencers, en particular, contribuyen a la difusión de mensajes manipulados al aprovecharse de las dinámicas de atención impulsadas por los algoritmos. Esto se evidenció en 2024, cuando un video manipulado sobre migrantes votando ilegalmente se volvió viral, reforzando marcos de «fraude electoral» y «amenaza migratoria».
En las elecciones de 2024, los autores observan un aumento en la actividad de grupos que promueven el marco de «elecciones manipuladas». Estos grupos reclutan voluntarios para recolectar y difundir evidencia que respalde estas narrativas, lo que podría generar rumores adicionales y alimentar demandas legales o intentos de socavar los resultados.
Finalmente, el artículo destaca la importancia de comprender los procesos de generación y propagación de rumores. Esta perspectiva permite empatizar con las personas que comparten rumores de buena fe y, al mismo tiempo, identificar cómo los propagandistas manipulan estas dinámicas. Este enfoque es crucial para que investigadores, periodistas y funcionarios electorales puedan responder de manera más eficaz a la desinformación.
Este volumen de acceso abierto, editado por Terry Flew y Fiona R. Martin, aborda en profundidad las cuestiones globales de política y gobernanza relacionadas con la regulación de plataformas digitales. El libro parte de una pregunta clave: ¿qué implicaría realmente la regulación de las plataformas digitales?
El auge de escándalos como el de Cambridge Analytica y la creciente reacción global contra los monopolios tecnológicos han llevado el tema de la gobernanza de internet al centro del debate político. Este libro responde a la necesidad de conectar el análisis crítico de las plataformas digitales con cuestiones de políticas públicas.
Amo las bibliotecas como un jardín de rosas de rosas entreabiertas devoro el aroma del perfume de sus estrechos pasillos donde se ocultan las luces y las sombras inciertas saboreo su ardor de amores prohibidos entre las hojas de las novelas donde las flores se marchitan
Amo las bibliotecas donde se tejen las palabras en su oscuro resplandor paso las manos por las estanterías toco el cuerpo de los libros siento las historias en mis dedos y la locura de los sentidos beso el rastrojo de los versos en los poemas incontenidos odas de insumisión sonetos del tiempo ardiente
Amo las bibliotecas que contienen corazón e invención y la memoria de los siglos acudo a su silencio de elixires y venenos ocultos preludios de Alejandría en el tallo del pensamiento y cuando me siento a leer es como si ya volara en motín y transgresión y nada me faltara
Amo las bibliotecas en una prisa insaciable de sus luces despiertas de eternidades, de vidas y mentes inquietas trazadas melancólicamente por las plumas y las plumas de los poetas lugares de lo absoluto donde busco y me pierdo de armonía y locura en nuestro tiempo oculto Amo las bibliotecas con pasión y locura y puedo morir de amor dentro de su destino