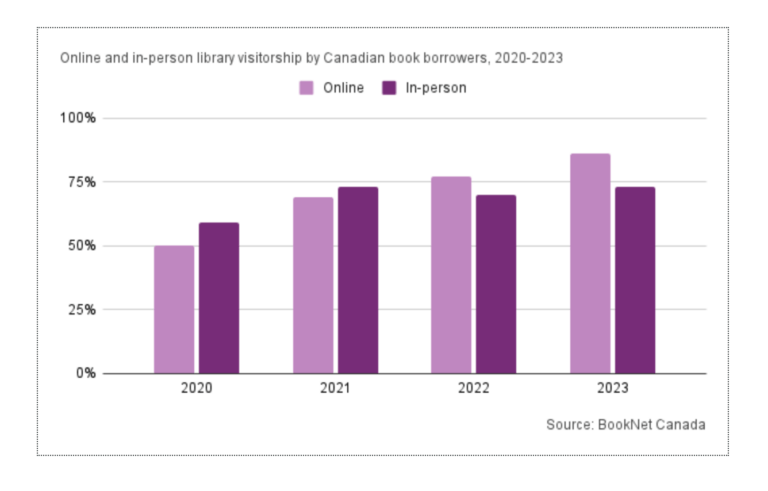
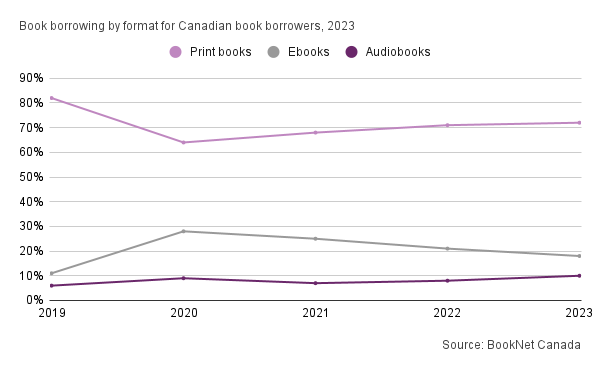
«Some things to consider when deciding whether to start building with “AI” in libraries and archives.» Inkdroid. Accedido 16 de abril de 2024. https://inkdroid.org/2024/03/12/ai/.
Se destacan cinco áreas de preocupación: sesgo, propiedad intelectual, verificabilidad, impacto en el trabajo humano y sostenibilidad. Señala que los modelos de aprendizaje automático (ML) se construyen con datos, lo que puede perpetuar sesgos y problemas de privacidad. Además, plantea inquietudes sobre la propiedad intelectual y el impacto ambiental de la IA, especialmente en términos de consumo energético y seguridad cibernética.
En un panel de trabajo sobre inteligencia artificial (IA), el autor reflexiona sobre sus experiencias y preocupaciones en relación con el uso de IA en bibliotecas y archivos. Aunque ha trabajado con modelos de IA y herramientas como Hugging Face y Google, estas experiencias solo han reforzado sus preocupaciones sobre la aplicación de estas tecnologías en el sector del patrimonio cultural.
Para abordar estas preocupaciones, el autor sugiere tácticas como evaluar la transparencia en el entrenamiento de modelos de IA, considerar qué contenido compartir con herramientas de IA generativas y priorizar la participación de los trabajadores afectados en la implementación de IA en el trabajo. También insta a las bibliotecas y archivos a buscar formas de reducir el consumo energético y a mejorar la seguridad y la privacidad en el uso de IA.
Sesgo
Los modelos de ML se construyen utilizando datos. Los avances recientes en Aprendizaje Profundo han sido en gran medida el resultado de aplicar algoritmos de décadas pasadas a cantidades cada vez mayores de datos recopilados de la web. Los datos utilizados para entrenar estos modelos son significativos porque los modelos necesariamente reflejan los datos que se utilizaron para crearlos. Desafortunadamente, las corporaciones son cada vez más reservadas sobre los datos que se han utilizado para entrenar estos modelos
Algunos conjuntos de datos comúnmente utilizados como CommonCrawl representan colecciones significativamente grandes de datos web, pero la web es un lugar grande, y se han tomado decisiones sobre qué sitios web se recopilaron. CommonCrawl no es representativo de la web en su totalidad. Además, los LLM codifican sesgos que están presentes en la sociedad actual. Usar y depender ciegamente de LLMs corre el riesgo de afianzar aún más estos sesgos y participar en el racismo sistémico.
A medida que los LLMs se utilizan para generar cada vez más contenido web, también existe el riesgo de que estos datos se recopilen nuevamente y se utilicen para entrenar modelos futuros. Este proceso se ha llamado Colapso del Modelo y se ha demostrado que conduce a un proceso de olvido. OpenAI lanzó una herramienta para identificar contenido generado con un LLM y tuvo que cerrarla 6 meses después porque no funcionaba, y no está claro siquiera si se puede hacer con fiabilidad. ¿Qué significaría entrenar solo estos modelos con datos anteriores a 2023.
Propiedad Intelectual
Dado que los LLMs se han construido con datos recopilados de la web, esto incluye muchos tipos de contenido, desde conjuntos de datos con licencia abierta diseñados para ser compartidos, hasta libros con derechos de autor como los encontrados en los conjuntos de datos de libros, que se rumorea que se han ensamblado a partir de bibliotecas en la sombra como Library Genesis y SciHub. En el último año, hemos visto varios juicios, incluido uno del Gremio de Autores que desafía el uso de materiales con derechos de autor por parte de OpenAI en la construcción de sus modelos GPT.
En cierto modo, este tipo de demandas no son nuevas en la web. Napster fue demandado por la Recording Industry Association of American; Google Books fue demandado por la Authors Guild a mediados de la década de 2000; Internet Archive ha sido demandado recientemente por su plataforma Open Library. Pero lo que hace que las LLM sean un poco diferentes es la forma en que transforman el contenido que han recopilado, en lugar de ponerlo a disposición del público textualmente. La Oficina de Derechos de Autor de EE.UU. publicó el año pasado un aviso de investigación para recabar información sobre el uso de materiales protegidos por derechos de autor en herramientas de IA.
New York Times también ha interpuesto una demanda porque OpenAI utilizó millones de sus noticias publicadas abiertamente para entrenar sus modelos sin licencia. OpenAI está intentando negociar contratos de licencia a posteriori con muchas grandes empresas.
El funcionamiento de los LLM representa un gran cambio en la evolución del ecosistema web. Los motores de búsqueda como Google rastrean las páginas web para indexarlas y ofrecen a los usuarios resultados de búsqueda que enlazan con el sitio web original. Del mismo modo, las plataformas de redes sociales han proporcionado un lugar para debatir contenidos web compartiendo enlaces a los mismos, lo que lleva a otros usuarios al editor web.
En el paradigma LLM, los usuarios nunca abandonan la interfaz ChatGPT y el editor original queda completamente al margen del círculo virtuoso. Los LLM están recopilando los bienes comunes de la web y amenazan con ahogar las mismas fuentes de contenido que utilizaban. Los editores perderán la posibilidad de saber cómo se utilizan sus contenidos.
Verificabilidad
Una de las razones por las que ChatGPT no enlaza a sitios web como citas es que no sabe a qué enlazar. En los LLM, la red neuronal no registra información sobre la procedencia de un dato concreto. A medida que los LLM se integran en herramientas de búsqueda más tradicionales, el reto consiste en conseguir que el texto generado sea verificable, en el sentido de que los resultados incluyan citas en línea, que deberían respaldar la afirmación en la que se utilizan.
La verificabilidad es importante para entender cuándo el contenido generado no se ajusta al mundo, lo que se denomina una «alucinación». También es importante para explicar por qué el modelo generó la respuesta que generó, cuando se intenta depurar por qué alguna interacción salió mal. La explicabilidad es un área de investigación activa en la comunidad de ML/AI, y no está claro que, dado el tamaño del modelo y el tamaño de los datos de entrenamiento, se pueda hacer que los modelos sean explicables, porque a un nivel fundamental no entendemos por qué funcionan. Se ha demostrado que las aplicaciones de IA generativa que incluyen citas no son fiables y proporcionan una falsa sensación de seguridad.
La falta de explicabilidad de los LLM plantea verdaderos problemas a las bibliotecas y archivos, cuya razón de ser es proporcionar a los usuarios documentos, ya sean libros, mapas, fotografías, grabaciones sonoras, películas, cartas, etc. Describimos estos documentos y los conservamos para facilitar el acceso a ellos, de modo que los usuarios puedan deducir su significado. Si utilizamos un LLM para generar una respuesta a una consulta o petición, y no podemos respaldar la respuesta con citas de estos documentos, esto supone un problema. Por ello, los profesionales de bibliotecas y archivos tienen un papel que desempeñar en la evaluación de cómo las herramientas de IA citan documentos como prueba.
Empleo
Parte de la propuesta de valor detrás de herramientas recientes de IA como Copilot de GitHub, ChatGPT o DALL-E es que democratizan el acceso a alguna habilidad, ya sea escribir código, ser autor de noticias o crear ilustraciones. Pero, ¿es democrático socavar sistemáticamente a los trabajadores creativos, robándoles su contenido sin haberles pedido utilizarlo en primer lugar?
Cuando se toma la decisión de utilizar estas herramientas, se está sustituyendo potencialmente la habilidad de una persona por un servicio. Además, estás atando tu propia organización a los caprichos de una corporación a la que nada le gustaría más que te desprendieras de la experiencia de tu organización y te hicieras completamente dependiente de su servicio. Es una trampa.
Si el pasado sirve de guía, también podemos esperar que los empleos creativos cualificados sean sustituidos por trabajos peor pagados que impliquen la limpieza mundana de los desaguisados que ha provocado la automatización. O en palabras del guionista C. Robert Cargill : «El miedo inmediato a la IA no es que los guionistas veamos nuestro trabajo sustituido por contenidos generados artificialmente. Es que nos paguen mal por reescribir esa basura en algo que podríamos haber hecho mejor desde el principio. Esto es a lo que se opone el WGA y lo que quieren los estudios.»
Los LLM como ChatGPT se construyen utilizando una técnica llamada Aprendizaje por Refuerzo con Retroalimentación Humana (RLHF). Lo importante aquí es la retroalimentación humana. ¿Quién proporciona esta información? ¿Son usuarios del sistema? ¿Qué tipos de sesgos sistemáticos introduce esta formación? ¿Se trata de «trabajadores fantasma» mal pagados?
Sostenibilidad
Probablemente, el aspecto más preocupante de la última oleada de tecnologías de IA es su impacto medioambiental. Los recientes avances en LLM no se han conseguido gracias a una mejor comprensión del funcionamiento de las redes neuronales, sino utilizando algoritmos ya existentes con cantidades ingentes de datos y recursos informáticos. Este entrenamiento puede llevar meses y debe repetirse para mantener los modelos actualizados.
Al parecer, el entrenamiento inicial de GPT-4 requirió 100 millones de dólares. El entrenamiento se basa en unidades de procesamiento gráfico (GPU), que son más rápidas que las CPU para los tipos de cálculo que exigen los LLM, pero requieren hasta cuatro veces más energía para funcionar. Los centros de datos necesitan agua para refrigerarse, a veces en entornos donde escasea. Esto no es sólo un problema para el entrenamiento de los modelos, es un problema mayor para su consulta, que se ha estimado entre 60 y 100 veces más en términos de utilización de energía. Otro problema que acecha aquí es la falta de datos de los centros de datos que proporcionen transparencia sobre lo que está ocurriendo.
¿Es esta realmente la dirección correcta en la que debemos dirigirnos cuando intentamos reducir los costes energéticos a nivel mundial para limitar el calentamiento global?
La industria tecnológica está incentivada para intentar que las infraestructuras de IA sean más eficientes. Pero es probable que se mantenga la paradoja de Jevons: el progreso tecnológico aumenta la eficiencia con la que se utiliza un recurso, pero la caída del coste de uso induce un aumento de la demanda suficiente como para que se incremente el uso del recurso.
Seguridad y privacidad
La IA generativa es una tecnología de doble uso. A los expertos les preocupa cada vez más que se utilice para crear desinformación, así como interacciones falsas en línea. Hemos tenido casos judiciales en los que los escritos presentados por abogados contenían citas de casos que no existían. Las robo-llamadas de voz generadas por IA han sido declaradas ilegales por el uso de herramientas de IA para suplantar la voz de Biden. Los malos actores pueden manipular imágenes y vídeos para dirigirse a grupos específicos porque las herramientas son más potentes y accesibles. Hay formas posibles de mitigar esto utilizando fuentes de información fiables y formas demostrables de compartir la procedencia de los medios.
Dado que los mecanismos de generación de contenidos de los LLM son inexplicables, son susceptibles de sufrir ataques como el que Simon Willison denomina «prompt injection«. En este caso, se crea un mensaje para subvertir el diseño original del sistema y generar la respuesta deseada. Esto tiene serias ramificaciones para el uso de la tecnología LLM como pegamento entre otros sistemas automatizados. De hecho, esto fue demostrado recientemente por investigadores que utilizaron las API de OpenAI y Google para ejecutar código arbitrario y filtrar información personal.
:focal(1500x1043:1501x1044)/https://tf-cmsv2-smithsonianmag-media.s3.amazonaws.com/filer_public/20/03/20034334-1cfa-484e-8d8e-f3658dbf3e62/gettyimages-673348704.jpg)