
En la clínica del arte de leer, no
siempre el que tiene mejor vista lee mejor.
Ricardo Piglia El último lector
En la clínica del arte de leer, no
siempre el que tiene mejor vista lee mejor.
Ricardo Piglia El último lector

«Borges inventa al lector como héroe a partir del espacio que se abre entre la letra y la vida. Y ese lector […] es uno de los personajes más memorables de la literatura contemporánea. El lector más creativo, más arbitrario, más imaginativo que haya existido desde don Quijote. Y el más trágico. En Borges ya no se trata de alguien que […] lee un libro sentado frente a una ventana. Se trata, en cambio, de alguien perdido en una biblioteca, que va de un libro a otro, que lee una serie de libros y no un libro aislado. Un lector disperso en la fluidez y el rastreo, que tiene todos los volúmenes a su disposición.»
Ricardo Piglia El último lector

Crownhart, Casey. “In a First, Google Has Released Data on How Much Energy an AI Prompt Uses.” MIT Technology Review, 21 ago. 2025. https://www.technologyreview.com/2025/08/21/1122288/google-gemini-ai-energy/
Un análisis basado en un informe técnico de Google que desglosa, por primera vez con detalle, la huella ambiental de las consultas al sistema de inteligencia artificial Gemini.
Google reveló que una consulta de texto típica —evaluada por la mediana de uso, es decir, aquella que se sitúa en el centro de la distribución de todos los prompts— consume aproximadamente 0,24 vatios-hora (Wh) de electricidad, genera cerca de 0,03 gramos de dióxido de carbono equivalente (gCO₂e) y requiere alrededor de 0,26 mililitros de agua, lo que equivale a unas cinco gotas. Para ponerlo en perspectiva cotidiana, la compañía equiparó esa cifra energética con la que emplea encender una televisión durante menos de nueve segundos. Estas métricas son parte de una metodología “full stack” desarrollada por Google, que intenta medir no solo el consumo directo de los procesadores de IA, sino también el uso de energía en sistemas auxiliares, memoria, infraestructura en reposo y refrigeración.
Google además destacó que la eficiencia de Gemini ha mejorado de forma dramática en el último año: desde mayo de 2024 hasta mayo de 2025, el consumo energético por consulta se redujo 33 veces y la huella de carbono se redujo 44 veces, mientras que, paralelamente, la calidad de las respuestas del modelo fue incrementándose. Estos avances se atribuyen a mejoras tanto de software —optimización de los modelos y algoritmos— como de hardware e infraestructura en los centros de datos de Google. La divulgación de estos datos se presenta como un paso hacia una mayor transparencia en el sector tecnológico, dada la creciente preocupación global por el impacto ambiental de los grandes modelos de IA y el uso masivo de energía de los centros de datos que los soportan.
Sin embargo, este enfoque también ha generado debate entre expertos ambientales. Algunos especialistas señalan que las cifras oficiales de Google, aunque impresionantes, pueden quedar cortas si no consideran factores indirectos más amplios, como la energía consumida por la generación eléctrica o el impacto del entrenamiento de los modelos a gran escala, que históricamente ha requerido volúmenes de energía y recursos muchísimo mayores que la inferencia diaria. Además, la extrapolación del consumo por prompt individual a escala global —con miles de millones de interacciones diarias— subraya que incluso pequeños valores por consulta pueden traducirse en una carga energética significativa cuando se multiplican por volumen de uso. Estas discusiones ponen de relieve la complejidad de medir con precisión el impacto ecológico de las tecnologías de IA y la necesidad de métricas estandarizadas en toda la industria.

«En aquellos años, la radio era el único cordón umbilical con el exterior. Sintonizar ciertas emisoras era un acto de fe. No se trataba solo de música, se trataba de pertenecer a una sociedad secreta que compartía códigos, vinilos importados y una urgencia por vivir que no cabía en los telediarios oficiales. El locutor no era un busto parlante, era el chamán que te entregaba la llave de un mundo prohibido.»
Diego A. Manrique «Jinetes en la tormenta»

«El lector adicto, el que no puede dejar de leer, y el lector insomne, el que está siempre despierto, son representaciones extremas de lo que significa leer un texto, personificaciones narrativas de la compleja presencia del lector en la literatura. Los llamaría lectores puros; para ellos la lectura no es solo una práctica, sino una forma de vida. Muchas veces los textos han convertido al lector en un héroe trágico (y la tragedia tiene mucho que ver con leer mal), un empecinado que pierde la razón porque no quiere capitular en su intento de encontrar el sentido.»
Ricardo Piglia El último lector

«La tecnología que mantiene internet funcionando no es neutral, y la que encontramos o instalamos en nuestros teléfonos móviles tampoco. En la última década, todas han evolucionado de una manera premeditada, con un objetivo muy específico: mantenerte pegado a la pantalla durante el mayor tiempo posible, sin que alcances nunca el punto de saturación».
Marta Peirano «El Enemigo Conoce el Sistema»

Ramm, M. (29 de diciembre de 2025). Meet the Retired Accountant Who Built a Street Library in Palermo. 1000 Libraries Magazine. Recuperado de https://magazine.1000libraries.com/meet-the-retired-accountant-who-built-a-street-library-in-palermo/
Pietro Tramonte, un contador jubilado cuya pasión por los libros transformó una calle de Palermo, Sicilia, en una biblioteca al aire libre de referencia cultural y comunitaria.
Tras retirarse de su carrera profesional, Tramonte decidió dedicar su tiempo y su extensa colección personal de libros a la comunidad local, creando un espacio accesible para todos los amantes de la lectura. Su iniciativa no fue planificada como un proyecto formal ni institucional, sino como una expresión espontánea de amor por la literatura y de deseo de compartir conocimiento. A partir de una pequeña selección de volúmenes en una calle lateral cerca del centro histórico, su biblioteca al aire libre fue creciendo con la contribución de vecinos, visitantes y aficionados a los libros, convirtiéndose con el paso del tiempo en un punto de encuentro para lectores de todas las edades.
Esta “biblioteca callejera” desafía las convenciones tradicionales de los espacios bibliotecarios al funcionar sin paredes ni horario de apertura estrictamente formal: los libros están disponibles a cualquier hora en estantes improvisados en la vía pública, y el intercambio o la donación de volúmenes se hace de manera libre y comunitaria. El proyecto de Tramonte se enmarca dentro de una tendencia más amplia de iniciativas de acceso abierto al libro y la lectura, que buscan acercar los textos impresos a comunidades urbanas y revitalizar el interés por los libros físicos en un contexto cada vez más digital. La presencia de esta biblioteca también ha atraído la atención de turistas y curiosos, quienes contribuyen con donaciones de libros y ayudan a difundir la historia de esta iniciativa única.
Además de proporcionar acceso gratuito a la lectura, la biblioteca de Tramonte ha generado un impacto cultural y social en Palermo al fomentar el encuentro entre personas diversas con intereses similares. El artículo enfatiza cómo un gesto aparentemente sencillo —poner libros al alcance de los transeúntes— puede convertirse en un símbolo de comunidad, diálogo intergeneracional y cooperación voluntaria. Esta iniciativa pone de relieve la importancia de la lectura como herramienta de inclusión cultural y apoyo comunitario, demostrando que la pasión individual por los libros puede dar lugar a proyectos colectivos significativos y sostenibles.

Marques, F. (2025, marzo). Use of fake email addresses leads to retraction of 45 articles by Brazilian scientists. Revista Pesquisa FAPESP. Recuperado de https://revistapesquisa.fapesp.br/en/use-of-fake-email-addresses-leads-to-retraction-of-45-articles-by-brazilian-scientists/
Se relata un caso significativo de problemas de integridad académica que llevó a la retracción de 45 artículos científicos firmados por un mismo investigador brasileño, el biólogo Guilherme Malafaia Pinto, del Instituto Federal Goiano (IF-Goiano), campus de Urutaí.
Los 45 trabajos fueron publicados en la revista Science of the Total Environment (STOTEN), editada por Elsevier, y su retirada no obedeció a errores experimentales o conclusiones erróneas, sino al compromiso del proceso de revisión por pares. Las notas de retracción señalaron que el sistema de evaluación había sido adulterado porque, aunque Malafaia sugería a revisores legítimos para sus manuscritos —práctica habitual en muchos procesos editoriales—, proporcionó direcciones de correo electrónico falsas para al menos tres de esos investigadores, de modo que las invitaciones de STOTEN llegaban a cuentas ficticias desde las cuales se devolvían opiniones favorables a la publicación. Como resultado, a pesar de que algunos artículos también recibieron evaluaciones de revisores independientes, Elsevier decidió retirar los trabajos al haber “perdido confianza en la validez o integridad” de los manuscritos.
La publicación también explora el contexto y las consecuencias del caso, tanto para el propio investigador como para la comunidad académica. Antes de este escándalo, Malafaia era un científico muy productivo, con casi 350 artículos publicados en una carrera de 15 años, supervisión de numerosos estudiantes de maestría y doctorado, y participación en comités editoriales de varias publicaciones, incluida STOTEN. Él niega haber manipulado deliberadamente la revisión de sus artículos, afirmando que usó direcciones de una base de datos china (CNKI) sin saber que eran falsas y que no tuvo participación directa en la redacción de los supuestos informes de revisión. En una carta abierta, argumentó que el problema fundamental era responsabilidad de los editores por no verificar los correos, y sugirió que sanciones menos drásticas que la retracción hubieran sido más apropiadas. Sin embargo, la situación ha tenido un impacto profundo en su reputación y la de sus colaboradores, muchos de los cuales ahora enfrentan cuestionamientos y el dilema de defender o distanciarse de los trabajos retractados; a la vez, la comunidad académica brasileña reflexiona sobre la importancia de fortalecer la ética y los sistemas de revisión para preservar la confianza en la ciencia.

Kang, Cecilia. New York Times. “From AI to Chips, Big Tech Is Getting What It Wants From Trump.” The New York Times, 28 de diciembre de 2025. https://www.nytimes.com/2025/12/28/technology/tech-trump.html
Donald Trump ha impulsado políticas favorables a las grandes empresas tecnológicas, particularmente en el contexto de la inteligencia artificial (IA) y los semiconductores.
En un contexto en que las políticas tecnológicas de Estados Unidos ocupan un papel central en la agenda política de 2025, el New York Times describe cómo la administración de Donald Trump ha implementado decisiones que favorecen ampliamente a las grandes empresas tecnológicas (Big Tech) en temas clave como inteligencia artificial (IA) y semiconductores. Aunque Trump llegó al poder con promesas de dinamizar la economía y restablecer la competitividad nacional, muchas de sus acciones han coincidido con las demandas y prioridades estratégicas de compañías como Nvidia, Google, Meta y otras, consolidando una alianza práctica entre el gobierno y el sector tecnológico que ha desbloqueado políticas regulatorias, cambios en comercio internacional y promoción de inversiones en infraestructura tecnológica.
Según la cobertura disponible, Trump ha eliminado o debilitado diversas restricciones a la exportación de chips semiconductores avanzados, como los fabricados por Nvidia, y ha promovido la expansión de la infraestructura tecnológica —incluidos centros de datos y producción de chips— con el argumento de mantener la competitividad estadounidense en la carrera global por la IA. Estos movimientos reflejan una clara alineación con las prioridades de Silicon Valley y otros gigantes tecnológicos, que han visto beneficios en la reducción de regulaciones y la apertura de mercados internacionales
Uno de los elementos más destacados de esta relación es la revocación o debilitación de restricciones que limitaban la exportación de chips avanzados y la regulación de tecnologías emergentes. La administración ha eliminado barreras regulatorias, acelerado la construcción de centros de datos y aprobado la venta de chips de IA más potentes en mercados sensibles, como China, medidas que muchos ejecutivos tecnológicos consideran esenciales para mantener la dominancia global de la industria estadounidense en IA y hardware. Esto se ha logrado tras esfuerzos coordinados entre líderes del sector y altos funcionarios de la Casa Blanca, que integran a la industria en posiciones de influencia técnica y política.
Además, el gobierno ha emitido órdenes ejecutivas y desarrollado un “AI Action Plan” nacional, orientado a impulsar la innovación de IA eliminando lo que Trump y sus asesores consideran barreras burocráticas y políticas que podrían frenar la competitividad de Estados Unidos frente a rivales como China. Estas políticas priorizan la expansión de la infraestructura tecnológica, la expansión de exportaciones y la coordinación federal única de normativas, reduciendo el papel de regulaciones estatales y enfocando el crecimiento en un marco de mercado libre que favorece a los grandes actores establecidos. Si bien estas medidas han sido aplaudidas por sectores empresariales como impulsores del crecimiento económico, también han generado críticas desde sectores que advierten sobre riesgos de falta de regulación, concentración de poder corporativo y posibles impactos negativos en la protección de derechos y seguridad pública.
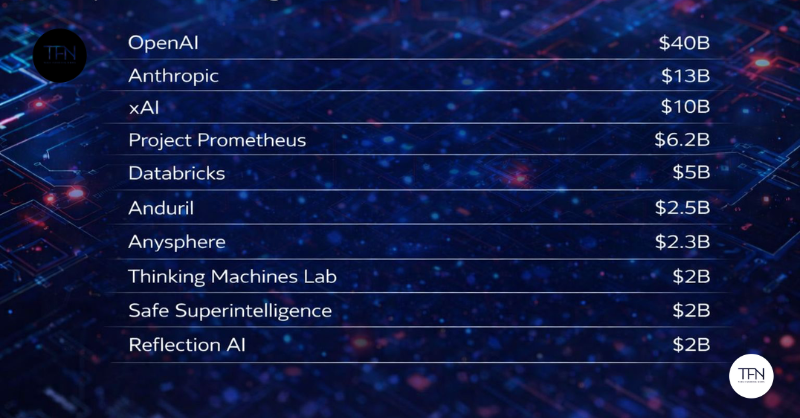
Prabhu, Abhinaya. “$84B Story: The 10 AI Mega-Rounds That Defined 2025.” TechFundingNews, 29 de diciembre de 2025. https://techfundingnews.com/openai-anthropic-xai-ai-funding-trends-2025/?utm_source=flipboard&utm_content=other
En 2025 el ecosistema de startups de inteligencia artificial (IA) en Estados Unidos ha alcanzado niveles excepcionales de financiación, concentrando enormes rondas de capital en un grupo reducido de empresas líderes.
Según TechFundingNews, las **10 mayores rondas de financiación de IA del año sumaron alrededor de 84 mil millones de dólares, evidenciando cómo los inversionistas están apostando decididamente por el desarrollo de modelos generativos, soluciones empresariales y plataformas de infraestructura de inteligencia artificial. Este patrón refleja una fuerte concentración de capital en proyectos que definen categorías tecnológicas emergentes y muestran gran potencial de crecimiento estratégico a largo plazo.
En el núcleo de estas inversiones está OpenAI, la organización detrás de ChatGPT y otros modelos de IA de propósito general, que lideró las rondas de 2025 con aproximadamente 40 mil millones de dólares recaudados en una sola ampliación de capital que sitúa su valoración posterior en unos 300 mil millones de dólares. Esta inyección de fondos —liderada por SoftBank con la participación de Microsoft, Coatue, Altimeter y Thrive— permitirá a OpenAI ampliar significativamente su infraestructura de cómputo, avanzar en investigación de punta y mejorar su capacidad para servir a más de 500 millones de usuarios semanales y a empresas que integran IA a gran escala.
De cerca le sigue Anthropic, fundada por los hermanos Daniela y Dario Amodei, que cerró una Serie F de 13 mil millones de dólares, elevando su valoración a aproximadamente 183 mil millones. Este capital reforzará la expansión internacional de sus productos de IA empresariales, profundizará la investigación en seguridad y ética de la IA y apoyará su crecimiento frente a competidores globales, consolidando su papel como uno de los laboratorios más influyentes en el espacio de la IA accesible y responsable.
Otra empresa que marcó tendencia es xAI, la compañía de inteligencia artificial fundada por Elon Musk. xAI recaudó más de 10 mil millones de dólares en financiación, alcanzando una valoración estimada en 200 mil millones de dólares, con el apoyo de inversores como Valor Capital, Qatar Investment Authority y Prince Al Waleed bin Talal. La financiación busca acelerar el despliegue de centros de datos propios y el desarrollo de modelos más eficientes (como Grok 4 Fast), que compitan directamente con los líderes del sector.
Además de estos gigantes, otras firmas tecnológicas especializadas también atrajeron importantes inversiones. Databricks obtuvo 5 mil millones para expandir su plataforma unificada de datos y análisis, mientras que empresas como Anduril (defensa autónoma), Anysphere (herramientas de productividad con IA), Thinking Machines Lab (fundada por ex-líderes de OpenAI), Safe Superintelligence (centrada en IA segura) y Reflection AI (automatización de código) recaudaron desde 2 hasta más de 2 mil millones cada una, reflejando la diversidad de aplicaciones y enfoques de la IA que están captando la atención de los fondos de capital riesgo.
En conjunto, estas rondas masivas muestran que la financiación de IA en 2025 no solo se trata de cantidades récord, sino de cómo se agrupan los recursos en empresas con grandes ambiciones tecnológicas y estratégicas. La concentración de capital en líderes de modelos generativos, infraestructura de datos y seguridad de IA sugiere que el mercado está apostando fuerte a que la próxima ola de innovación —y de cambio industrial— vendrá precisamente de estas plataformas dominantes.
