Editor-in-Chief, Nandita Quaderi, Vice President Editorial, y Web of Science Clarivate. «Mapping the Path to Future Changes in the Journal Citation Reports». Clarivate (blog), 7 de marzo de 2023. https://clarivate.com/blog/mapping-the-path-to-future-changes-in-the-journal-citation-reports/.
En julio de 2022, se cumplieron los planes para ampliar el Journal Impact Factor (JIF)™ a todas las revistas de la Web of Science Core Collection™ a partir de junio de 2023. Esto significa que este año, las revistas del Arts and Humanities Citation Index (AHCI)™ y del multidisciplinar Emerging Sources Citation Index (ESCI)™ en el Journal Citation Reports (JCR)™ recibirán un JIF por primera vez.
Recordamos que esta novedad obedece a dos motivos: Dar a todas las revistas de calidad un JIF proporcionará total transparencia a todos y cada uno de los artículos y citas que han contribuido al impacto académico de una revista, ayudando a demostrar su valor para la comunidad investigadora. También contribuirá a nivelar el terreno de juego para todas las revistas de calidad, incluidas las de acceso abierto, las de reciente creación o las especializadas, o las de ámbito regional y las del Sur Global.
Como resultado de este desarrollo, otras 9.000 revistas del JCR recibirán un JIF y se beneficiarán por primera vez de una página de perfil de revista mejorada. Además, se muestra el JIF con un decimal, en lugar de los tres decimales actuales, para animar a los usuarios a tener en cuenta otros indicadores y datos descriptivos del JCR a la hora de comparar revistas.
Clasificaciones por categorías en la versión 2023 del JCR
Este año se sugiere proporcionar clasificaciones por categorías y asignando cuartiles JIF solo para las revistas indexadas en el Science Citation Index Expanded (SCIE)™ y el Social Sciences Citation Index (SSCI)™.
También proporcionar clasificaciones separadas para las nueve categorías temáticas que están indexadas en múltiples ediciones. Por ejemplo, la Psiquiatría está incluida tanto en el SCIE como en el SSCI; este año, las revistas de Psiquiatría del SCIE seguirán clasificándose por separado de las revistas de Psiquiatría del SSCI.
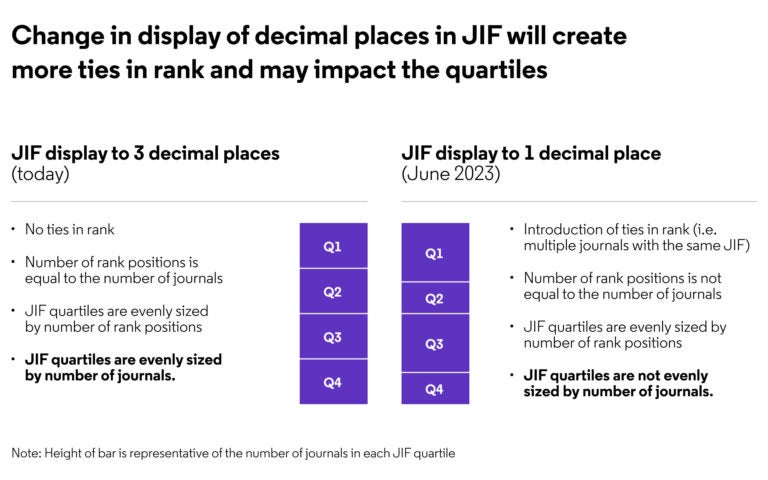
El hecho de que el JIF se muestre con un decimal hará que las clasificaciones estén más igualadas. Esto afectará a la distribución de los cuartiles del JIF, ya que los cuartiles se calculan en función del número de posiciones en el ranking de una categoría determinada, y no simplemente del número de revistas de una categoría dividida equitativamente en cuatro (Figura 1).
Fig. 1
La distribución por cuartiles ha dado lugar normalmente a que aproximadamente el 25% de las revistas estén contenidas en cada cuartil, ya que los empates han sido poco frecuentes. Sin embargo, al aumentar el número de empates, la distribución cambia. Las revistas empatadas en el mismo rango no pueden dividirse entre dos cuartiles y con el aumento del número de empates veremos que algunos cuartiles contendrán un número mayor o menor de revistas que en años anteriores.
La fórmula para calcular los cuartiles puede encontrarse aquí
¿Cómo serán las clasificaciones por categorías en 2024?
En la versión del JCR del próximo año, se añadirán las revistas AHCI y ESCI a las clasificaciones por categorías del JCR y se asignarán a cuartiles JIF. Ya no habrá rankings de categorías específicos para cada edición y, en su lugar, se creará un único ranking para cada una de nuestras 254 categorías que incluirá revistas de las cuatro ediciones (SCIE, SSCI, AHCI y ESCI). Una vez más, tomando Psiquiatría como ejemplo, se mostrará un único ranking de Psiquiatría que incluye revistas indexadas en SCIE, SSCI y ESCI.
En el caso de AHCI, se introducirá por primera vez clasificaciones para las 25 categorías únicas específicas de artes y humanidades. No habrá categorías específicas de ESCI; todas las revistas indexadas en ESCI entran dentro de las 254 categorías temáticas existentes en SCIE, SSCI y AHCI.
La inclusión de 9.000 revistas adicionales de AHCI y ESCI en las clasificaciones por categorías del JIF también afectará a las clasificaciones generales y a la distribución por cuartiles el próximo año.
¿Por qué se está adoptando un enfoque gradual?
Se está ampliando el JIF a AHCI y ESCI y pasando a una visualización de un punto decimal del JIF este año y, a continuación, se incluirán las revistas AHCI y ESCI en las clasificaciones por categorías el próximo año, con el fin de proporcionar transparencia sobre cómo cada uno de estos cambios afecta por separado a las clasificaciones y cuartiles del JIF.
Esta es la primera de una serie de actualizaciones y análisis sobre cómo la ampliación del JIF a más revistas de calidad se traducirá en cambios en las clasificaciones y cuartiles en JCR y explicará cómo los usuarios pueden utilizar los filtros de JCR para ver clasificaciones que sólo incluyan revistas de ediciones de interés. Marque esta página y permanezca atento a nuevas actualizaciones.