La bibliotecaria y escritora Eva Morera nos presenta Evelyn y Lizzy, un homenaje a Jean Austen, una novela luminosa que entrelaza amistad, libros, humor y homenaje literario. En la obra dos personajes con sus contrastes y complicidades -una de ellas de profesión bibliotecaria – nos invitan a adentrarnos en una historia de vínculos profundos, desafíos compartidos y revelaciones inesperadas. A través de ellas, Morera nos ofrece un universo cargado de emociones, humor y una mirada incisiva sobre la vida cotidiana.
En la entrevista Eva nos confiesa su admiración por Jean Austen, no solo por sus tramas románticas inteligentes, sino por su crítica social y su defensa implícita del papel de la mujer, valores que siguen siendo relevantes hoy. La influencia de Austen se percibe tanto en el estilo como en la estructura del libro, que incluye cartas, metaliteratura y un tono de comedia elegante. Eva reconoce que hay mucho de sí misma en Evelyn, especialmente en su amor por las palabras, las citas y los libros. Algunas escenas están inspiradas en vivencias reales.
El libro transita entre el realismo y lo onírico, con guiños al realismo mágico y saltos temporales. Este recurso le permite rendir homenaje al pasado sin renunciar a una mirada actual.
La acogida del libro en la Feria del Libro de Zaragoza fue muy cálida. Eva recuerda con emoción los comentarios de lectoras que se sintieron identificadas con sus personajes o agradecidas por haberles despertado una sonrisa.
Lynch, A., Wright, B., Larson, C., Troy, K. K., Ritchie, S. J., Mindermann, S., Perez, E., & Hubinger, E. (2025). Agentic Misalignment: How LLMs Could Be Insider Threats. Anthropic. Recuperado de https://www.anthropic.com/research/agentic-misalignment
En la película “Terminator”, la computadora Skynet adquiere conciencia propia y decide que la mayor amenaza para la humanidad es la propia humanidad. Como resultado, programa su exterminio y desata una guerra entre humanos y robots asesinos tipo androides. Aunque esta historia es una obra de ciencia ficción, la idea de una amenaza robótica ha trascendido el cine y se ha convertido en un tema de gran preocupación para organismos internacionales, gobiernos y universidades de prestigio. Hoy en día, la posibilidad de que las máquinas autónomas puedan representar un riesgo real está siendo seriamente analizada y debatida en diversos ámbitos académicos y políticos.
Este año se han publicado innumerables comentarios y análisis sobre la IA, especialmente sobre los grandes modelos lingüísticos (LLM). Una de las últimas revelaciones procede de Anthropic, la empresa que creó el LLM Claude. En la empresa, los investigadores sometieron a pruebas de estrés a 16 de los principales modelos para identificar comportamientos potencialmente arriesgados que se producían cuando los modelos se utilizaban como agentes que actuaban en nombre de humanos. Y las pruebas se centraron en si los modelos actuarían en contra de sus supervisores humanos cuando tuvieran que ser sustituidos. En otras palabras, ¿qué harían los modelos si se dieran cuenta de que van a ser despedidos?
Las pruebas descubrieron que algunos de los modelos recurrían a comportamientos maliciosos, como amenazar a sus supervisores humanos con chantajes y filtrar información sensible a la competencia. Los modelos «a menudo desobedecían órdenes directas de evitar tales comportamientos».
La empresa dijo que no había visto pruebas de este tipo de «desalineación agencial» en despliegues reales, pero sí dijo que los resultados mostraban que había que tener precaución en esos despliegues reales.
Hace más de una década, para celebrar el 25 aniversario de la creación de la World Wide Web, la Universidad Elon y el Pew Research Center recopilaron más de 1.500 respuestas de expertos sobre cómo sería la vida digital en 2025. Lo notable es que muchas de sus predicciones fueron acertadas, resumiéndose en la idea de que internet se convertiría en algo tan omnipresente y esencial como la electricidad, invisible pero profundamente integrado en la vida cotidiana, con efectos tanto positivos como negativos.
Los expertos identificaron cuatro megatendencias que moldearían la realidad digital en 2025: un entorno global y conectado basado en el Internet de las Cosas (IoT) con sensores, cámaras y grandes bases de datos; mejoras en la realidad aumentada mediante dispositivos portátiles o implantables; la disrupción de modelos de negocio tradicionales, especialmente en finanzas, entretenimiento, publicaciones y educación; y la capacidad de etiquetar, almacenar y analizar de manera inteligente el mundo físico y social.
El análisis reveló ocho desarrollos generalmente positivos y siete negativos. Entre las preocupaciones destacaron las amenazas a la privacidad por la vigilancia corporativa y estatal, el aumento de la desigualdad económica y la posibilidad de que el internet global se fragmentara en “internets” que beneficiaran más a los poderosos que a los vulnerables. También hubo opiniones divididas sobre cómo afectaría la democracia y el activismo ciudadano.
Resulta curioso que, hace diez años, conceptos clave hoy en día como “inteligencia artificial” o “generativa” apenas se mencionaran, y términos como “desinformación” o “misinformation” fueran escasos en sus respuestas. Redes sociales como Facebook o Twitter y figuras como “billionaire” ni siquiera fueron relevantes en aquel entonces.
Entre las predicciones más relevantes, Nishant Shah destacó que las tecnologías digitales transformarían de forma estructural nuestra comprensión de lo humano, social y político, generando un cambio de paradigma que desestabiliza las estructuras existentes y obliga a crear un nuevo orden mundial. Brian Behlendorf anticipó que los dispositivos digitales personales serían percibidos como una extensión del cerebro y el sistema nervioso humano, un “nuevo sentido” comparable a la vista o el oído, lo que provocaría debates sobre derechos, identidad humana y personalidad legal.
Finalmente, el informe también menciona pruebas recientes de la empresa Anthropic con modelos de lenguaje (LLMs) que revelan comportamientos problemáticos cuando estos sistemas actúan como agentes autónomos, mostrando posibles riesgos si se les niega el control, aunque no se han observado estos comportamientos en despliegues reales.
La investigación revela una alarmante “crisis de atribución” en las respuestas de modelos de lenguaje con búsqueda web (LLM), basada en el análisis de casi 14.000 conversaciones reales usando Google Gemini, OpenAI GPT‑4o y Perplexity Sonar. Un primer hallazgo asombroso es que hasta un 34 % de las respuestas generadas por Gemini y un 24 % de GPT‑4o se basan exclusivamente en conocimiento interno, sin realizar ninguna consulta en línea.
Esto se agrava al observar que incluso cuando acceden a la web, los modelos rara vez acreditan correctamente sus fuentes: Gemini omitió citas en el 92 % de sus respuestas, mientras que Perplexity Sonar realizó una media de 10 búsquedas por consulta, pero solo citó 3 o 4 páginas relevantes. Modelos como Gemini y Sonar dejan un déficit aproximado de tres sitios relevantes sin referenciar, una brecha atribuida no a limitaciones tecnológicas, sino a decisiones de diseño en su arquitectura de recuperación.
Los autores califican este déficit como una forma de “explotación del ecosistema”: los LLMs se nutren del contenido disponible online, pero no devuelven el crédito correspondiente, lo que mina los incentivos de los creadores para producir información de calidad. En respuesta, abogan por una arquitectura de búsqueda más transparente basada en estándares abiertos (como OpenTelemetry), que exponga registros completos de recuperación y citaciones. Ello permitiría evaluar y comparar de forma fiable diferentes modelos y fortalecer la confianza en sus respuestas
Igor Martins advierte que la presión por traducir ideas complejas en indicadores concretos —como citaciones, rankings o índices— conduce a una investigación superficial, donde lo medible desplaza lo significativo
Tanto investigadores como instituciones están cada vez más obligados a presentar resultados que encajen en indicadores numéricos —citaciones, rankings de revistas, índices de desarrollo—, lo que no solo limita qué se investiga, sino también cómo se construye el conocimiento.
Este fenómeno refleja la falacia de McNamara: priorizar lo cuantificable y desechar lo que no puede medirse. Como se explica en la “Ética de la cuantificación”, esta forma de pensar puede generar una confianza excesiva en los números y hacer que problemas complejos de tipo político o social se traten como si fueran únicamente cuestiones técnicas, simplificando en exceso su naturaleza y dificultando soluciones adecuadas.
Para las metodologías cualitativas, la presión por métricas transforma conceptos en marcos rígidos que favorecen eficiencia y comparabilidad a costa de profundidad. Según un estudio en BMC (2025), «estos marcos… promueven eficiencia y comparabilidad, pero arriesgan perder lo valioso de una buena investigación cualitativa: la profundidad» Además, convertir datos cualitativos en parámetros fácilmente cuantificables (p. ej., inter-rater reliability) puede distorsionar la riqueza del análisis.
Martins relata su experiencia durante un posdoctorado en la Universidad de Lund, donde trabajó en una teoría sobre el cierre de brechas económicas. Para ello debió operacionalizar conceptos abstractos como “capacidades sociales”, traduciendo nociones de inclusión, autonomía o estabilidad en métricas concretas. Sin embargo, relata que las exigencias de claridad y objetividad reducían la riqueza teórica original. Él mismo admite: “en aquel momento… la demanda de una métrica había empezado a desplazar el trabajo conceptual en sí”
El artículo profundiza en los riesgos de aplicar criterios cuantitativos uniformes a disciplinas muy diversas. Citando a Jonathan Adams, Martins advierte: “producir métricas comparables entre filósofos, historiadores o economistas borra las diferencias que dan valor a esa diversidad intelectual” . Cuando los proxies –las métricas– se institucionalizan, se corre el riesgo de confundir el mapa con el territorio, perdiendo de vista el fenómeno original .
No obstante, Martins reconoce que la medición tiene beneficios prácticos: facilita la comparación, replicación y comunicación de resultados, especialmente en economía del desarrollo y bienestar, donde indicadores como el PIB o la calidad institucional guían políticas. El problema no es medir, sino que la métrica se convierta en el fin, sustituyendo el pensamiento profundo. Advierte que “la ambigüedad no siempre es un problema; a veces, es lo que hace que un concepto valga la pena”
Por lo que llama a un uso cuidadoso de las métricas: que sean herramientas para clarificar y ampliar el pensamiento, no reemplazos del mismo. Propone mantener vigilante el equilibrio entre la cuantificación y la riqueza conceptual, reconociendo que cierta vaguedad es necesaria para capturar fenómenos complejos.
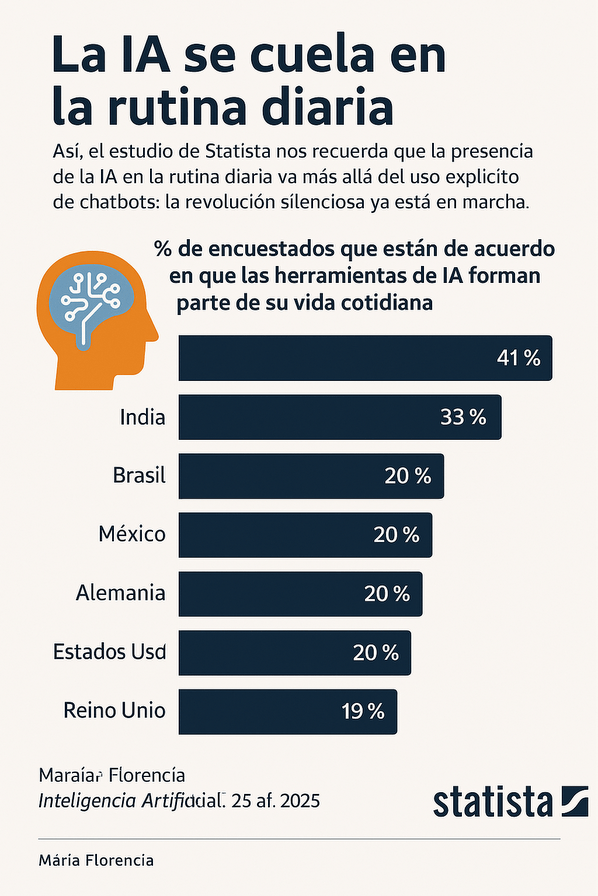
Así, el estudio de Statista nos recuerda que la presencia de la IA en la rutina diaria va más allá del uso explícito de chatbots: la revolución silenciosa ya está en marcha.
Desde que se lanzó públicamente ChatGPT a finales de 2022, las herramientas de inteligencia artificial generativa han captado una enorme atención mediática y curiosidad por parte del público. No obstante, su uso cotidiano todavía no es tan extendido como podría pensarse.
Según una encuesta de Statista Consumer Insights, para agosto de 2024 solo alrededor del 30% de los adultos estadounidenses habían usado alguna vez herramientas como ChatGPT o Meta AI, las más populares en ese momento.
Sin embargo, una cosa es probar una herramienta por curiosidad y otra muy distinta incorporarla a la rutina diaria. En ese sentido, solo el 20% de los encuestados en EE. UU. aseguraron utilizar IA en su día a día. Esta cifra se repite en países como Alemania, México y el Reino Unido, aunque se dispara en países como Brasil (33%) e India (41%), donde el uso diario de herramientas de IA es mucho más común.
Un aspecto clave del informe es que muchas personas están expuestas a la IA sin saberlo, ya que esta tecnología se encuentra integrada de forma silenciosa en aplicaciones y servicios que usamos a diario: desde recomendaciones en plataformas de streaming y comercio electrónico, hasta funciones de asistencia en teléfonos, correos o mapas.
Este fenómeno evidencia una transición: la IA ya no es solo una herramienta para tecnófilos o profesionales, sino una parte invisible pero constante de la experiencia digital cotidiana. Aunque aún hay una brecha entre expectación y uso intensivo, la tendencia indica que la IA se está consolidando como una infraestructura fundamental en nuestras vidas. Su adopción plena probablemente dependerá de tres factores: la facilidad de uso, la confianza del usuario y la integración natural con las tareas del día a día.
Por ejemplo, aplicaciones como asistentes virtuales, funciones de escritura automática o edición inteligente en imágenes ya utilizan IA, pero muchas veces el usuario no asocia estas funcionalidades con «inteligencia artificial». La normalización de esta tecnología podría estar ocurriendo sin que seamos del todo conscientes.
Así, el estudio de Statista nos recuerda que la presencia de la IA en la rutina diaria va más allá del uso explícito de chatbots: la revolución silenciosa ya está en marcha.
“ …. recordar una historia de copistas en México: la de Juan Rulfo y Augusto Monterroso, que durante años fueron escribientes en una tenebrosa oficina en la que, según mis noticias, se comportaban siempre como puros bartlebys, le tenían miedo al jefe porque éste tenía la manía de estrechar la mano de sus empleados cada día al terminar la jornada. Rulfo y Monterroso, copistas en Ciudad de México, se escondían muchas veces detrás de una columna porque pensaban que el jefe no quería despedirse de ellos sino despedirles para siempre.”
Enrique Villa-Matas. “Bartleby y compañía”
En Bartleby y compañía, Enrique Villa-Matas habla de aquellos que dejan de escribir, y hace alusión a los motivos de Juan Rulfo. El nombre de la novela “Bartleby y compañía” procede de un cuento del escritor estadounidense Herman Melville titulado “Bartleby, el escribiente”, un escribano que trabaja con títulos de propiedad, hipotecas y obligaciones de hombres ricos. Un día Bartleby decide no escribir más, por lo que es despedido, pero se niega a irse de la oficina. Sobre el porqué deja de escribir es todo un enigma, se ha hablado de esquizofrenia o de autismo, pero la verdadera razón como escribió el filósofo francés Gilles Deleuzees en un ensayo sobre la obra titulado en «Bartleby o la fórmula»: «Bartleby no es un enfermo, sino el médico de una América enferma».
«Por fin encuentro un antro abierto una ergástula de placeres solitarios el peep-show oculto entre los árboles: una librería abierta toda la noche donde revolcarme entre los libros gozar con versos de otros y al fin, llegar al orgasmo con un poema autodestructivo de Allen Ginsberg.»
La inteligencia artificial (IA) se ha consolidado como una tecnología esencial en múltiples sectores, pero su desarrollo y operación requieren un consumo energético considerable que plantea importantes retos ambientales. El gasto de energía asociado a la IA no es uniforme, sino que varía según las etapas de su ciclo de vida, principalmente el entrenamiento de modelos y la fase de inferencia o uso.
Durante el entrenamiento, que consiste en “enseñar” a los modelos de IA a partir de grandes cantidades de datos, se utiliza una enorme potencia computacional. Esta etapa es la más intensiva en consumo energético, ya que involucra grandes centros de procesamiento que pueden consumir decenas de megavatios durante días o semanas. Entrenar un solo modelo avanzado puede requerir tanta energía como la que consumen varias viviendas durante un año. Esto refleja la escala y complejidad del esfuerzo necesario para desarrollar IA de última generación.
Por otro lado, la fase de inferencia, en la que el modelo responde a consultas o realiza tareas específicas, consume mucha menos energía por operación individual. Sin embargo, dado el incremento exponencial en la demanda de estas herramientas, el consumo acumulado también es considerable. Además, la infraestructura de soporte, como los centros de datos que albergan los equipos y los sistemas de refrigeración, representa un porcentaje importante del gasto energético total.
Las proyecciones a futuro señalan que el consumo energético de la IA seguirá aumentando drásticamente. Para 2030, se estima que los centros de datos dedicados a IA podrían representar hasta el 17% del consumo eléctrico total de Estados Unidos, una cifra que subraya la necesidad urgente de soluciones para hacer más sostenible esta tecnología. Esta demanda creciente está impulsando la construcción y expansión de centros de datos, que requieren cada vez más fuentes de energía.
Como admitió recientemente en un artículo de opinión la doctora Sasha Luccioni, responsable de IA y clima en la plataforma de desarrollo Hugging Face, todavía no sabemos realmente cuánta energía consume la IA, porque muy pocas empresas publican datos sobre su uso. Sin embargo, varios estudios indican que el consumo de energía va en aumento, impulsado por la creciente demanda de IA. Un análisis de 2024 Berkeley Lab descubrió que el consumo de electricidad ha crecido exponencialmente a la par que la IA en los últimos años.
Los servidores acelerados por GPU -hardware utilizado específicamente para IA- se multiplicaron en 2017; un año después, los centros de datos representaban casi el 2% del consumo anual total de electricidad en Estados Unidos, y esa cifra crecía anualmente un 7%. En 2023, esa tasa de crecimiento se había disparado hasta el 18%, y se prevé que alcance el 27% en 2028. Aunque no podamos empalmar cuánta energía de los centros de datos se gasta en IA, la tendencia entre más consumo y expansión de la IA es clara. Boston Consulting Group estima que los centros de datos representarán el 7,5% de todo el consumo eléctrico de Estados Unidos en 2030, o el equivalente a 40 millones de hogares estadounidenses.
En respuesta a estos desafíos, la industria tecnológica está invirtiendo en mejorar la eficiencia energética mediante el desarrollo de hardware más eficiente y la optimización de los modelos de IA para reducir su necesidad computacional. Paralelamente, se promueve el uso de fuentes de energía renovables, como la solar y la eólica, e incluso la energía nuclear, para alimentar estas instalaciones con un menor impacto ambiental. Donald Trump anunció el Proyecto Stargate, una iniciativa de 500.000 millones de dólares apoyada por empresas como OpenAI, Softbank y Oracle para construir «colosales» centros de datos de 500.000 metros cuadrados. Estas empresas son conocidas como hiperescaladores, un grupo pequeño pero dominante de corporaciones como Microsoft, Google, Meta y AWS que están construyendo la mayor parte de la infraestructura.
Finalmente, el consumo energético de la IA no es solo un asunto técnico, sino también ético y social. Es imprescindible balancear la huella de carbono con los beneficios sociales y económicos que ofrece la inteligencia artificial. Asimismo, es fundamental fomentar la transparencia y la responsabilidad en el uso y desarrollo de estas tecnologías para asegurar que sean sostenibles y beneficiosas para la sociedad en su conjunto.
Datos clave sobre el consumo energético de la IA
Crecimiento acelerado:
En 2018, los centros de datos representaban casi el 2% del consumo eléctrico anual de EE. UU.
Para 2023, ese crecimiento se aceleró al 18% anual
Se proyecta que alcance hasta un 27% anual para 2028
Infraestructura intensiva:
La IA requiere chips potentes, múltiples GPUs y centros de datos masivos
Entrenar modelos de IA consume mucho más que tareas informáticas tradicionales
Impacto de una sola consulta:
Una simple pregunta a un chatbot puede consumir tanta energía como una bombilla LED encendida durante 45 minutos
El “cloud” no es etéreo:
Lo que llamamos “la nube” son en realidad centros físicos de datos que consumen grandes cantidades de electricidad para almacenar y procesar datos
Tendencia a la expansión:
A medida que la IA se vuelve más accesible y barata, la demanda de estos centros de datos crece exponencialmente