Worlock, David. “Notation: The AI Scientist — From Research to Article Writing to Peer Review.” David Worlock Blog, abril de 2026. David Worlock Blog
“The AI Scientist”
https://sakana.ai/ai-scientist-nature
El artículo aborda uno de los cambios más profundos que está experimentando el ecosistema científico contemporáneo: la aparición de sistemas de inteligencia artificial capaces de ejecutar de forma autónoma prácticamente todo el ciclo de producción científica. El texto analiza especialmente el desarrollo de “The AI Scientist”, un sistema presentado en la revista Nature y diseñado por la empresa japonesa Sakana AI, capaz de generar hipótesis, diseñar experimentos, escribir código, analizar datos, redactar artículos completos y participar incluso en procesos de revisión por pares.
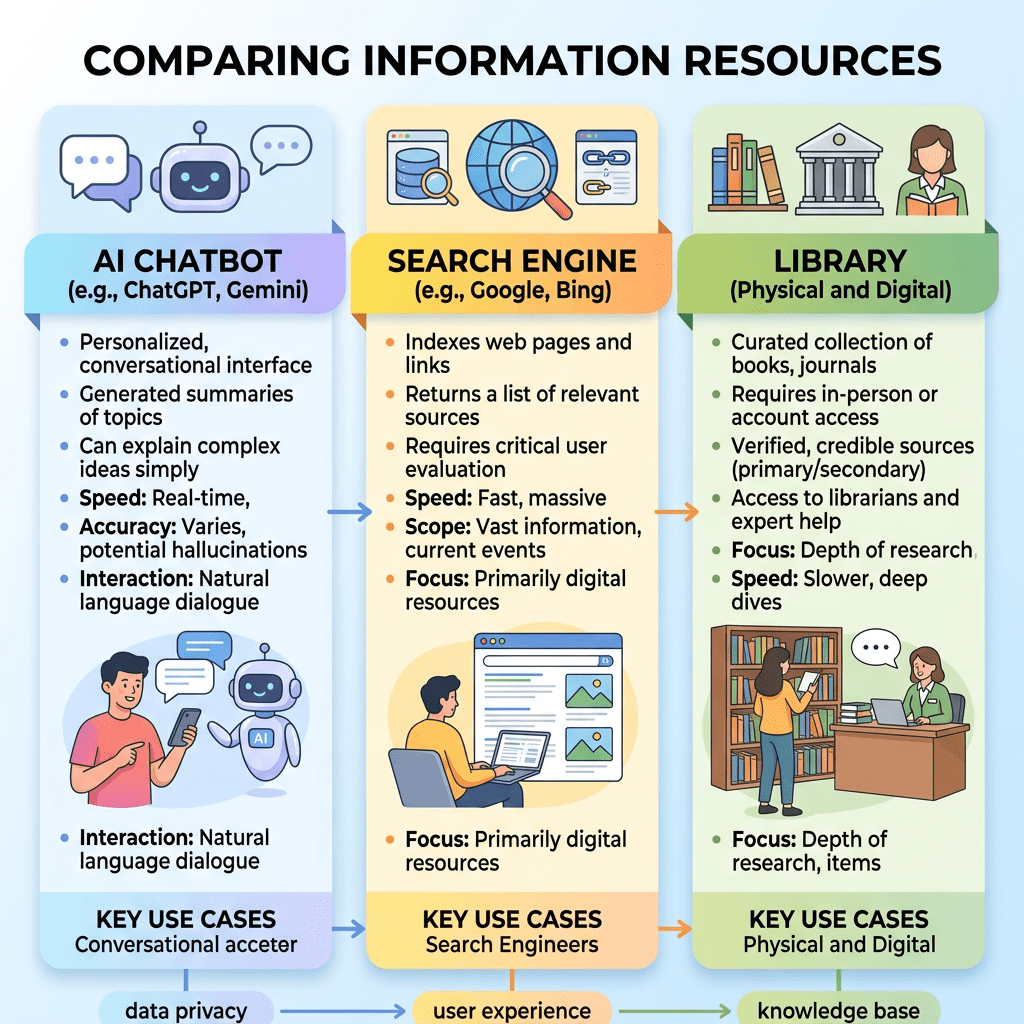
Worlock interpreta este avance no como una simple mejora de productividad, sino como una transformación estructural del modelo tradicional de investigación académica. Según expone, durante décadas la inteligencia artificial había funcionado principalmente como una herramienta de apoyo puntual —por ejemplo, para análisis estadísticos, minería de datos o predicción molecular—, pero ahora comienza a actuar como un agente científico relativamente autónomo. La cuestión central deja de ser “cómo ayuda la IA al investigador” para convertirse en “qué partes del trabajo científico continúan dependiendo exclusivamente del juicio humano”. Esta transición representa un cambio epistemológico profundo en la manera de producir conocimiento.
Uno de los aspectos más relevantes del artículo es la descripción detallada del flujo de trabajo de estos sistemas. El modelo automatizado identifica líneas de investigación potenciales, consulta bibliografía existente, descarta ideas ya exploradas y formula nuevas hipótesis. Posteriormente genera código experimental, ejecuta simulaciones, procesa resultados y redacta un manuscrito completo en formato académico. Incluso incorpora sistemas de evaluación interna inspirados en la revisión por pares. Todo ello ocurre con una intervención humana mínima.
El texto subraya especialmente el impacto simbólico que supuso que uno de estos artículos generados por IA superara una ronda de revisión en un workshop asociado a la conferencia internacional International Conference on Learning Representations. Aunque posteriormente el artículo fue retirado por motivos de transparencia experimental, el hecho evidenció que la frontera entre producción científica humana y producción algorítmica comienza a desdibujarse.
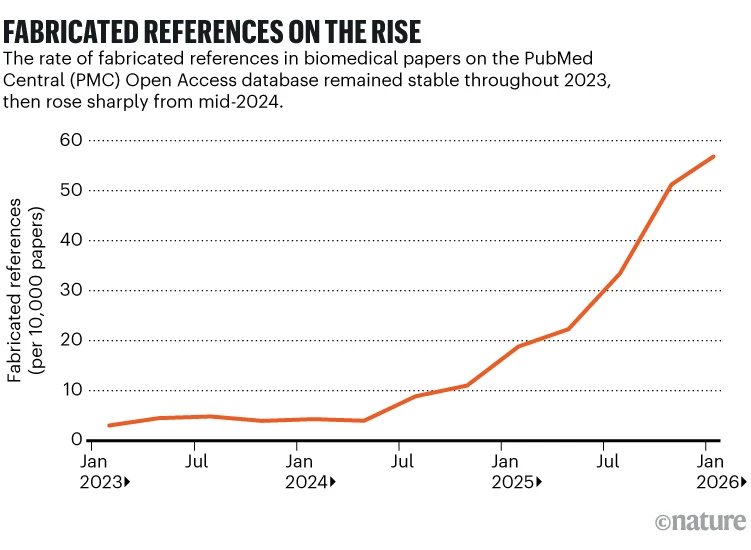
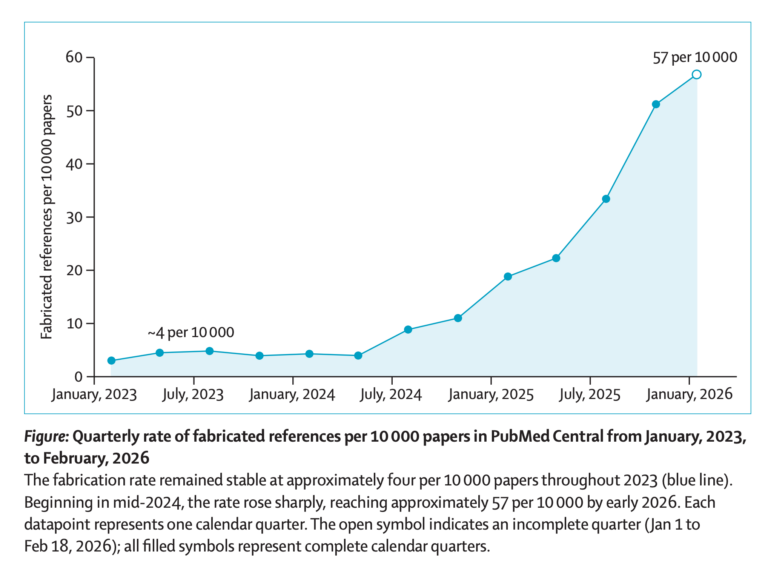
Worlock también explora las implicaciones editoriales y bibliométricas de este fenómeno. Si una IA puede producir artículos científicos en cuestión de horas o minutos, el volumen de publicaciones podría multiplicarse exponencialmente. El problema no sería únicamente cuantitativo, sino también cualitativo: la literatura académica podría verse inundada de trabajos técnicamente correctos pero científicamente irrelevantes. Este riesgo conecta con la creciente preocupación por el colapso de los sistemas tradicionales de revisión por pares, ya sobrecargados por el aumento constante de manuscritos.
El artículo relaciona esta situación con el modelo de incentivos del sistema académico contemporáneo, basado en métricas de productividad, índices de citación y presión por publicar. La IA no crea este problema, pero sí lo amplifica. En un contexto de “publish or perish”, la automatización de la escritura científica puede incentivar la proliferación de investigaciones redundantes, superficiales o generadas simplemente para aumentar currículos académicos. Diversos expertos citados en trabajos recientes advierten que la producción masiva automatizada podría erosionar la credibilidad del sistema científico si no se establecen mecanismos robustos de control y gobernanza.
Otro eje fundamental del análisis es el futuro de la revisión por pares. Worlock señala que las editoriales y revistas científicas comienzan a debatir hasta qué punto la IA puede participar en tareas de evaluación editorial. Algunos estudios recientes muestran que muchos investigadores aceptarían herramientas de IA como apoyo para mejorar manuscritos antes del envío, pero siguen rechazando la idea de sustituir completamente el juicio humano en la evaluación científica. La preocupación principal reside en que los modelos generativos tienden a producir textos plausibles y coherentes incluso cuando contienen errores metodológicos, referencias inexistentes o interpretaciones engañosas.
El texto también profundiza en cuestiones éticas y filosóficas. Si una IA produce un descubrimiento relevante, ¿quién es el autor? ¿Quién asume la responsabilidad de errores, sesgos o fraudes? ¿Puede hablarse realmente de creatividad científica en un sistema automatizado? Worlock sugiere que estamos entrando en una etapa en la que el investigador humano podría transformarse progresivamente en supervisor, editor o curador del trabajo algorítmico, desplazando el centro de la actividad científica desde la producción textual hacia la validación crítica y la supervisión epistemológica.
En esta línea, el artículo conecta con debates recientes sobre transparencia y trazabilidad en el uso de modelos generativos en ciencia. Algunos investigadores ya proponen que las interacciones completas entre científicos y modelos de IA se publiquen como material suplementario, de modo que pueda evaluarse qué parte del razonamiento corresponde al sistema automatizado y cuál al investigador humano.
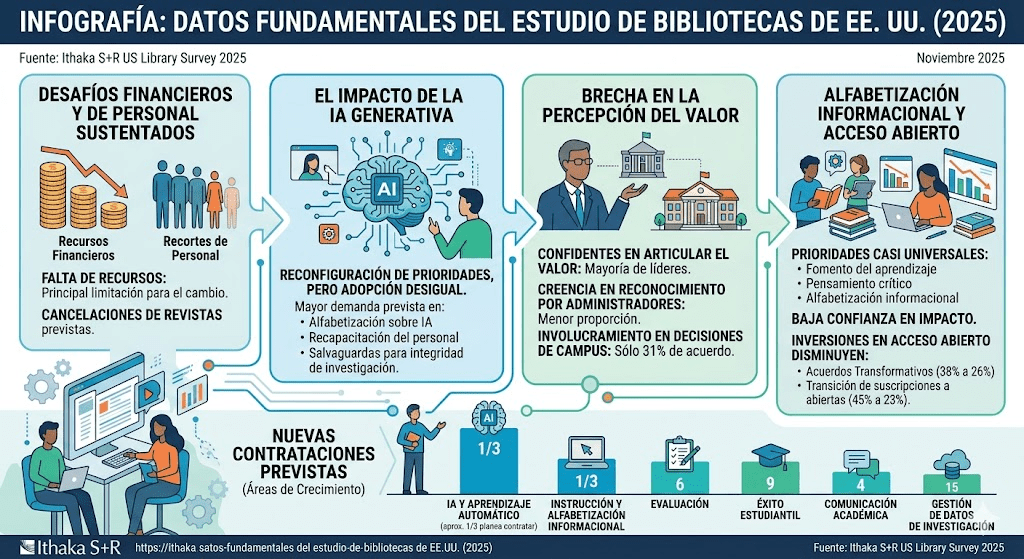
La reflexión final de Worlock es especialmente significativa para bibliotecas, editoriales académicas y gestores de información científica. El desafío ya no consiste únicamente en almacenar y difundir conocimiento, sino en distinguir conocimiento valioso dentro de un entorno potencialmente saturado por producción automatizada. En este nuevo escenario, cobran aún más importancia funciones como la curación de contenidos, la evaluación de calidad, la alfabetización informacional y la preservación de la integridad científica.
El artículo presenta una visión amplia y crítica sobre la transición hacia una ciencia parcialmente automatizada. Más que anunciar el reemplazo inmediato de los investigadores humanos, plantea la emergencia de un nuevo ecosistema híbrido en el que inteligencia humana e inteligencia artificial convivirán dentro de procesos de investigación, publicación y evaluación científica cada vez más interconectados.