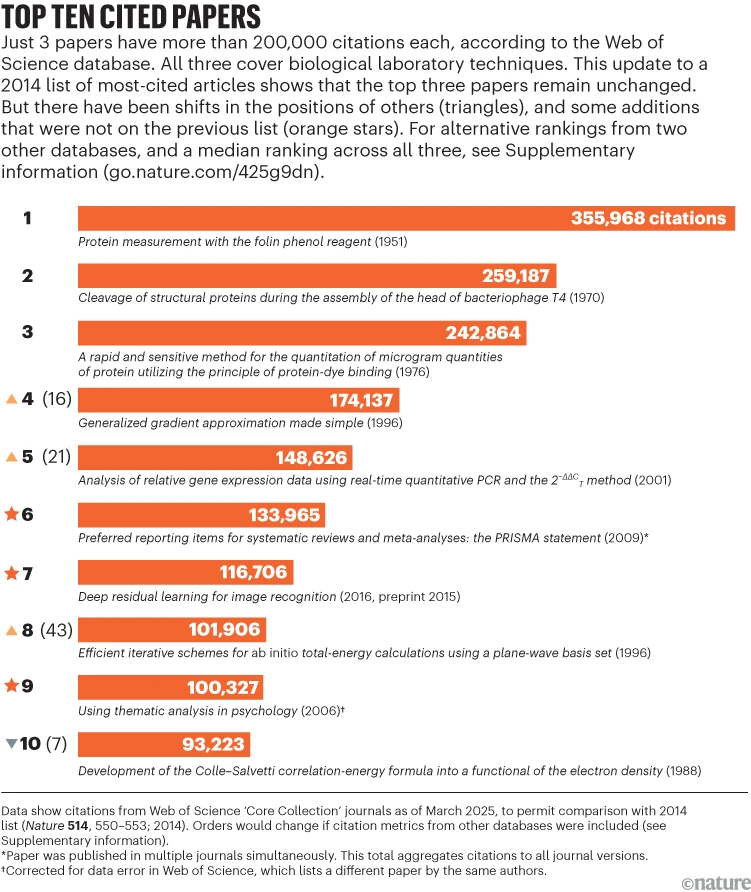
Van Noorden, Richard. «Science’s Golden Oldies: The Decades-Old Research Papers Still Heavily Cited Today.» Nature, April 15, 2025. https://doi.org/10.1038/d41586-025-01126-8
Se analiza cómo ciertos trabajos clave han mantenido su relevancia a lo largo del tiempo, destacando especialmente los más citados en los artículos publicados en 2023.
El análisis revela que, aunque muchas publicaciones recientes sobre inteligencia artificial (IA), software científico y métodos para mejorar la calidad de la investigación dominan hoy las listas de referencias, algunos estudios más antiguos continúan siendo referenciados con frecuencia. Entre ellos, se incluyen trabajos de los años 90, como el que describe una arquitectura temprana de redes neuronales llamada long short-term memory (LSTM) de 1997, que sigue siendo citado con frecuencia debido a su eficiencia en el procesamiento de datos.
También se destacan investigaciones sobre materiales publicadas en 1996 que, gracias a su innovador enfoque para calcular interacciones electrónicas en materiales, siguen siendo citadas en una proporción significativa. Un cuarto de las citas de este trabajo se han dado en los últimos dos años, mostrando cómo el impacto de investigaciones antiguas puede continuar creciendo a medida que nuevas generaciones de científicos las descubren y aplican.
El estudio muestra cómo algunas publicaciones, incluso décadas después de su publicación, siguen siendo fundamentales para el avance de la ciencia, gracias a su base teórica sólida y la continua aplicabilidad de sus descubrimientos. Esto subraya la importancia de identificar y reconocer las «piedras angulares» del conocimiento científico, independientemente de su antigüedad.
| Rank | Title | Number of Citations (Range) |
|---|---|---|
| 1 | Deep residual learning for image recognition (2016) | 19,826–33,339 |
| 2 | Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide (2021) | 10,952–24,830 |
| 3 | Attention is all you need (2017) | 9,395–19,348 |
| 4 | Generalized gradient approximation made simple (1996) | 14,338–17,540 |
| 5 | Using thematic analysis in psychology (2006) | 10,660–17,347 |
| 6 | The PRISMA 2020 statement: an updated guideline for reporting systematic reviews (2021) | 13,115–13,443 |
| 7 | Analysis of relative gene expression data using real-time quantitative PCR and the 2−ΔΔCT method (2001) | 11,851–13,082 |
| 8 | Random forests (2001) | 6,266–12,294 |
| 9 | Efficient iterative schemes for ab initio total-energy calculations using a plane-wave basis set (1996) | 10,063–10,789 |
| 10 | Long short-term memory (1997) | 2,394–12,355 |
Fuente: Nature (2025).