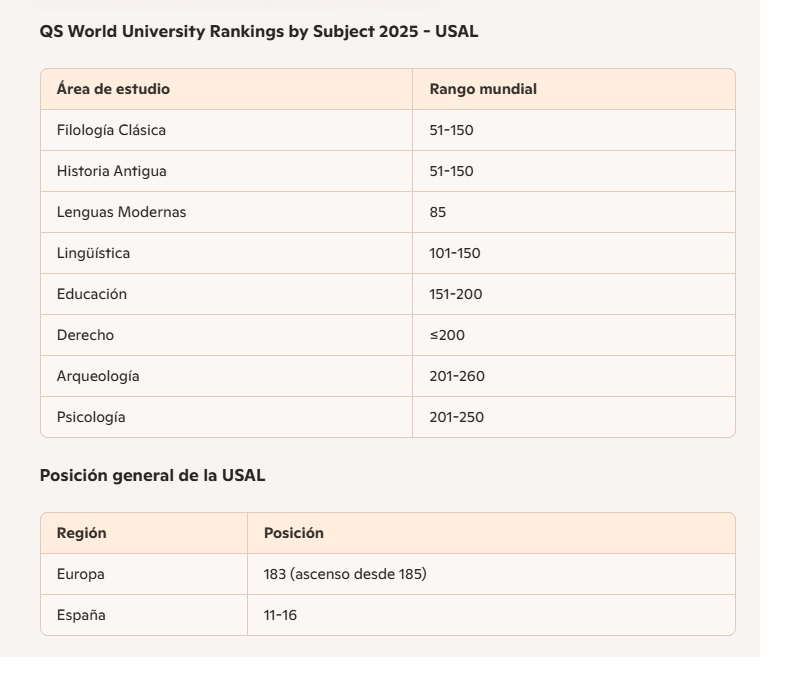
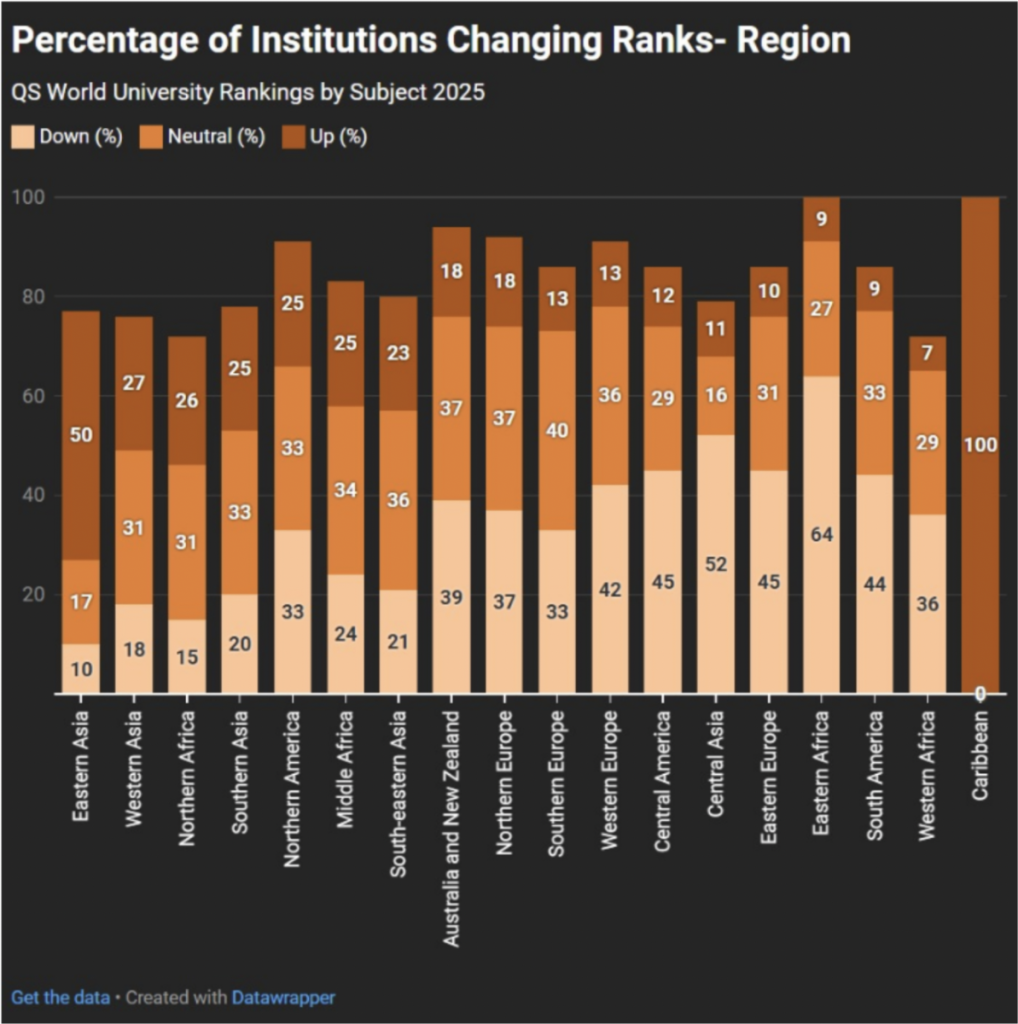
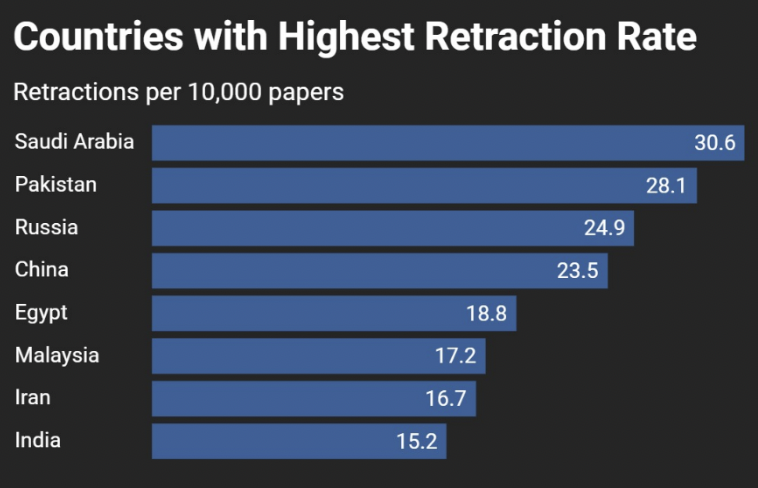
Lim, Aaron Tay. “Testing AI Academic Search Engines (1).” Musings about Librarianship (blog), March 2025. https://musingsaboutlibrarianship.blogspot.com/2025/03/testing-ai-academic-search-engines-1.html
Este artículo es el primero de una serie dedicada a desarrollar un marco para evaluar motores de búsqueda académicos impulsados por inteligencia artificial (IA). El autor destaca que, antes de establecer métodos de evaluación, es esencial definir claramente qué se entiende por “motor de búsqueda académico con IA”. Sin una definición precisa, las comparaciones entre herramientas pueden resultar vagas o engañosas.
Los motores de búsqueda académicos con inteligencia artificial (IA) son herramientas diseñadas específicamente para facilitar el acceso, la comprensión y la organización del conocimiento científico. A diferencia de los buscadores tradicionales que se limitan a localizar documentos mediante coincidencias literales de palabras clave, estos motores aplican tecnologías avanzadas de IA para ofrecer resultados más pertinentes y comprensivos, adaptándose mejor a las necesidades de investigadores, estudiantes y profesionales académicos.
Estos motores integran IA de diversas formas, incluyendo:
- Búsqueda semántica (más allá de los métodos tradicionales de palabras clave).
- Generación de respuestas directas con citas mediante técnicas como RAG (Retrieval Augmented Generation).
- Resúmenes automáticos de documentos.
- Síntesis de estudios en matrices o tablas.
- Identificación de autores clave, artículos fundamentales y tendencias emergentes.
Una de sus principales características es la búsqueda semántica, que permite interpretar la intención detrás de una consulta más allá de las palabras exactas empleadas. Esto significa que pueden entender sinónimos, relaciones conceptuales y contextos temáticos, lo que mejora significativamente la relevancia de los resultados. Además, muchos de estos sistemas utilizan técnicas como RAG (Retrieval Augmented Generation) para generar respuestas directas a preguntas específicas, acompañadas de citas de fuentes relevantes, lo cual agiliza el proceso de revisión de la literatura.
Otra capacidad destacada es la de elaborar resúmenes automáticos de artículos académicos, extrayendo la información clave de textos largos y complejos para facilitar su comprensión rápida. También pueden sintetizar hallazgos de múltiples estudios en tablas comparativas o matrices, lo cual es especialmente útil para revisiones sistemáticas o estudios de meta-análisis. Por último, estos motores son capaces de identificar autores influyentes, artículos fundamentales y tendencias emergentes en distintas áreas del conocimiento, contribuyendo así a una mejor navegación por el creciente universo de la literatura científica.
El autor propone clasificar las herramientas en cuatro grandes grupos.
- Motores de búsqueda académicos con IA como Elicit.com, Scite assistant*, Consensus, Scopus AI, Primo Research Assistant, Perplexity.ai. Estas herramientas están diseñadas específicamente para la búsqueda académica y utilizan modelos de lenguaje de última generación para generar respuestas con citas, permitir consultas en lenguaje natural y combinar búsquedas semánticas con técnicas de recuperación de información.
- Modelos de lenguaje con capacidad de búsqueda, como ChatGPT, Microsoft Copilot, Geinmi, Claude, DeepSeek, Grok. Aunque estos sistemas pueden responder a preguntas sobre temas académicos, su objetivo principal no es funcionar como buscadores científicos. A menudo generan respuestas que no provienen de una búsqueda real, lo que puede derivar en errores o invenciones, conocidas como “alucinaciones”.
- Sistemas de mapeo bibliográfico basados en citas, como Connected Papers, ResearchRabbit, Litmaps*, Citation Gecko, Incitefu. Estas herramientas no funcionan como buscadores tradicionales, sino como sistemas de recomendación que, a partir de uno o varios documentos “semilla”, generan mapas visuales de literatura relacionada utilizando relaciones de citación entre artículos.
- Herramientas de asistencia a la escritura académica, como Keenius, Jenna,ai. Estas aplicaciones están orientadas a ayudar a redactar textos científicos, ofreciendo sugerencias de redacción con base en citas reales, y suelen incorporar interfaces de escritura más parecidas a un procesador de texto que a un motor de búsqueda.
Descripción de cada herramienta:
Elicit: Un asistente de investigación que ayuda a analizar y sintetizar información de artículos académicos, acelerando tareas como la extracción de datos y la creación de revisiones sistemáticas.
Scite Assistant: Una herramienta que contextualiza citas académicas, destacando si apoyan o contradicen un argumento, ideal para revisiones de literatura.
Consensus: Un asistente que utiliza IA para responder preguntas basadas en evidencia científica, extrayendo información de artículos académicos.
Scopus AI: Basado en la base de datos Scopus, esta herramienta genera resúmenes y revisiones de literatura académica.
Primo Research Assistant: Aunque no encontré información específica, parece ser un asistente enfocado en la investigación académica.
Perplexity.ai: Un motor de búsqueda que utiliza IA para responder preguntas con explicaciones claras y referencias.
ChatGPT: Un modelo de lenguaje desarrollado por OpenAI que puede generar texto, responder preguntas y realizar tareas creativas.
Microsoft Copilot: Tu compañero de IA creado por Microsoft, diseñado para ayudarte en tareas de productividad, creatividad y aprendizaje.
Geinmi: La propuesta de Meta para la IA
Claude: Un asistente de IA desarrollado por Anthropic, enfocado en conversaciones naturales y tareas complejas.
DeepSeek: La web de IA China
Grok: modelo de inteligencia artificial generativa (IA) creado por xAI, la empresa de Elon Musk, que se utiliza como un asistente de IA en X.
Connected Papers: Una herramienta para explorar conexiones entre artículos académicos y descubrir investigaciones relevantes.
ResearchRabbit: Ayuda a encontrar y organizar artículos académicos relacionados con un tema específico.
Litmaps: Una herramienta para visualizar y rastrear la evolución de la investigación académica a través de mapas de citas.
Citation Gecko: Permite explorar redes de citas para encontrar artículos relevantes.
Inciteful: Una herramienta para analizar redes de citas y descubrir investigaciones relacionadas.
Keenius: No encontré información específica sobre esta herramienta.
Jenna.ai: Jenni AI es una herramienta de inteligencia artificial que asiste en la redacción académica
Lens.org: Una plataforma para buscar y analizar patentes y literatura académica.
OpenAlex: Una base de datos abierta que proporciona información sobre artículos académicos, autores e instituciones.