MusicLM es un modelo que genera música de alta fidelidad a partir de descripciones textuales como «una relajante melodía de violín acompañada de un riff de guitarra distorsionado». MusicLM plantea el proceso de generación de música condicional como una tarea de modelado jerárquico secuencia a secuencia, y genera música a 24 kHz que se mantiene constante durante varios minutos.
La revolución de la IA: En 2022, ChatGPT, DALL-E 2 y otras IA avanzadas capaces de generar texto o imágenes impresionantes en respuesta a comandos de usuario ganaron popularidad. Sin embargo, no fueron las primeras IA generativas ni los únicos ejemplos de lo que las redes neuronales pueden hacer.
¿Qué hay de nuevo? La novedad es MusicLM, un generador de música basado en IA presentado por Google en enero de 2023. Esta tecnología representa uno de los ejemplos más impresionantes, ya que puede generar clips de hasta 5 minutos de duración basados en descripciones de texto, logrando que la música suene más parecida a algo que podría grabar un humano que otros generadores de IA.
MusicLM supera a los sistemas anteriores tanto en calidad de audio como en adherencia a la descripción textual. Además, demostramos que MusicLM puede condicionarse tanto al texto como a una melodía, ya que puede transformar melodías silbadas y tarareadas según el estilo descrito en un pie de texto.
¿Cómo funciona? Google entrenó MusicLM con más de 280.000 horas de música proveniente de MuLan, un modelo entrenado para vincular la música con descripciones escritas en lenguaje natural. Luego, crearon MusicCaps, un conjunto de datos públicamente accesible con más de 5.500 clips de música para evaluar el generador de música de IA.
En comparación con otros generadores de música basados en texto, como Mubert y Riffusion, Google enfrentó a MusicLM a través de varias métricas cuantitativas para evaluar la calidad auditiva y la adherencia a una descripción de texto. Según un documento compartido por Google en el servidor de preimpresión arXiv, MusicLM superó a las otras IA en todos los aspectos evaluados.
Mirando hacia el futuro: Aunque MusicLM puede producir audio que suena más cercano a la música escrita por humanos, aún no puede replicar estructuras de canciones tradicionales y la calidad vocal es deficiente. Google destaca la necesidad de trabajos futuros para abordar estos problemas y mejorar la calidad general del audio. Además, aproximadamente el 1% de la producción de MusicLM se puede emparejar aproximadamente con el audio en sus datos de entrenamiento, un problema que debe abordarse antes de su lanzamiento público.
En 1947, en la India, se difundió una gran sensación de entusiasmo en todo el país por la construcción de una nueva nación, comenzando desde sus pilares culturales: las escuelas y las bibliotecas. Este es el contexto para la publicación de «The Organization of Libraries» de Ranganathan. Con este libro, Ranganathan tiene como objetivo «relacionar la organización de la biblioteca con la educación» y proporcionar «una descripción breve de la técnica bibliotecaria». La estructura trifásica de la obra muestra claramente su objetivo de ser un medio de promoción para un nuevo sistema nacional de bibliotecas en la India, y el papel que deberían desempeñar las bibliotecas escolares en este proceso. La Parte 1 está dedicada a la Biblioteca y la Educación, la Parte 2 a la Práctica Bibliotecaria y la Parte 3 al Sistema Nacional de Bibliotecas.
Ingravalle, Grazia. 2024. Archival Film Curatorship: Early and Silent Cinema from Analog to Digital. Amsterdam University Press. https://doi.org/10.5117/9789463725675.
Archival Film Curatorship es el primer libro que investiga los archivos cinematográficos en la intersección de las historias institucionales, la historiografía del cine antiguo y mudo y el comisariado de archivos. Examina tres instituciones a la vanguardia de la experimentación con la exhibición y el comisariado de películas. El Eye Film Museum de Ámsterdam, el George Eastman Museum de Rochester (Nueva York) y el National Fairground and Circus Archive de Sheffield (Reino Unido) sirven como lugares ejemplares de mediación histórica entre el cine antiguo y mudo y la era digital. Una serie de elementos, desde protocolos de conservación a tecnologías de exhibición y desde arquitecturas museísticas a discursos curatoriales en blogs, catálogos y entrevistas, conforman lo que el autor teoriza de forma innovadora como el dispositivo hermenéutico del archivo. Archival Film Curatorship ofrece a los estudiosos del cine y la conservación una visión única de las cambiantes definiciones, historias y usos del medio cinematográfico por parte de quienes se encargan de preservarlo y presentarlo a las nuevas audiencias de la era digital.
Ciula, Arianna, Øyvind Eide, Cristina Marras, y Patrick Sahle. 2023. Modelling Between Digital and Humanities: Thinking in Practice. Open Book Publishers. https://doi.org/10.11647/obp.0369.
Este volumen presenta una exploración de las Humanidades Digitales (DH), un campo centrado en la transformación recíproca de las tecnologías digitales y la erudición en humanidades. La práctica de la modelización, que implica la traducción de intrincados sistemas de conocimiento en modelos computacionales, es fundamental para la investigación en DH. Este libro aborda una cuestión fundamental: ¿Cómo puede desarrollarse un lenguaje eficaz para conceptualizar y orientar la modelización en el campo de las humanidades?
La modelización, con sus raíces históricas, conlleva significados polifacéticos influidos por diversos contextos disciplinarios. Modelling Between Digital and Humanities conecta de forma innovadora el DH con la tradición histórica del pensamiento basado en modelos en las humanidades, los estudios culturales y las ciencias. Intenta remodelar los marcos interpretativos contextualizando las prácticas de modelización de las DH en un panorama conceptual más amplio.
A través de una exploración de los modelos digitales, visuales y de datos, el libro afirma que el DH tiene el potencial de ser la piedra angular de un nuevo paradigma de alfabetización cultural. Al sondear la interacción entre tecnología y pensamiento, el libro sitúa en última instancia al DH como catalizador de percepciones culturales transformadoras.
«Nadie sabe cómo será el futuro, pero sí sabemos cómo no será. Sabemos que no será muchos niños sentados en escritorios con lápiz y papel, escribiendo todo el día»
Seymour Papert, profesor de educación en el MIT y cofundador de su influyente Media Lab y Artificial Intelligence Lab.
Han pasado más de 50 años desde que Seymour Papert empezó a desafiar nuestras creencias sobre cómo debían ser las escuelas. Su visión era que los niños aprendieran construyendo cosas que les apasionaran. Así nació la pedagogía construccionista. Como suele ocurrir, las ideas de Papert se consideraron disruptivas en su momento e indignaron a los diseñadores de planes de estudios tradicionales. Y aunque hoy en día son ampliamente aceptadas e incluso celebradas, aún nos queda mucho camino por recorrer para ponerlas en práctica. Lamentablemente, seguimos «jugueteando mientras Roma arde», como sugería el título de su último libro inacabado.
Papert estaba fascinado por los engranajes. Como más tarde se dio cuenta, esto le ayudó mucho a comprender y apreciar las matemáticas en la escuela. «Un Montessori moderno podría proponer, si se convence por mi historia, crear un conjunto de engranajes para niños. Así, cada niño podría tener la experiencia que yo tuve», escribió en 1980 en su primer libro sobre educación, «Mindstorms: Children, Computers, and Powerful Ideas». «Pero esperar esto sería perder la esencia de la historia. Me enamoré de los engranajes. (…) Algo muy personal sucedió, y no se puede asumir que se repetiría para otros niños exactamente de la misma manera».
En cambio, propuso que las computadoras podrían convertirse en los engranajes para que todos se enamoraran. Son lo suficientemente flexibles para que cada niño pueda crear lo que realmente le interesa. Y esto es lo que lo inspiró a crear el lenguaje de programación Logo. Era mucho más que una plataforma de codificación: ¡podía controlar una tortuga robótica con un bolígrafo! Los niños podían escribir código para hacer que la tortuga se moviera y dibujara diferentes formas. En otras palabras, podían convertir lo que estaban trabajando en algo real.
Papert luego trabajó con LEGO para experimentar más, y más tarde el fabricante de juguetes nombró a sus kits educativos robóticos Mindstorms en reconocimiento a su influyente libro. Avancemos un par de décadas, y uno de los estudiantes de Papert y luego asociado en el MIT, Mitch Resnick, creó Scratch, un lenguaje de programación basado en bloques para niños que cuenta con casi 60 millones de usuarios hoy. En 2015, Micro:bit nació en la misma línea: el microcontrolador con sensores y un lenguaje de programación basado en bloques fácil de usar se puede utilizar de un millón de maneras para interactuar con objetos del mundo real.
Estas invenciones de tecnología educativa sirven al mismo propósito: ayudar a los niños a aprender construyendo sobre lo que les interesa, en lugar de estandarizar el proceso de aprendizaje y hacer que todos se enfoquen en lo mismo. Los niños pueden trabajar hacia un objetivo en el que creen, en lugar de estudiar solo porque alguien lo dijo.
El advenimiento del aprendizaje activo Papert fue más que un investigador ingenuo enamorado de la nueva tecnología y obsesionado con las computadoras. Sus ideas sobre la educación se basaron en un sólido fondo teórico. Al principio de su carrera, estudió el desarrollo cognitivo de los niños en la Universidad de Ginebra con el renombrado filósofo y psicólogo suizo Jean Piaget, y esta colaboración condujo finalmente a los fundamentos de la pedagogía construccionista.
Piaget es venerado por generaciones de maestros inspirados por la creencia de que los niños no son recipientes vacíos para llenar de conocimiento (como lo sostiene la teoría pedagógica tradicional), sino constructores activos del conocimiento —pequeños científicos que constantemente crean y prueban sus propias teorías sobre el mundo», escribió Papert sobre su mentor. «A medida que la tecnología digital brinda a los niños una mayor autonomía para explorar mundos más grandes, las ideas que él pioneriza se vuelven más urgentemente relevantes para padres y educadores».
Desde la construcción de ideas hasta la creación de cosas. Ambos creían que los niños deberían desempeñar un papel activo en el proceso de aprendizaje. Como explicó Piaget, «los niños tienen una comprensión real solo de aquello que inventan ellos mismos, y cada vez que intentamos enseñarles algo demasiado rápido, les impedimos reinventarlo por sí mismos». En otras palabras, adquieren conocimiento interactuando con el mundo y construyendo estructuras de conocimiento basadas en sus propias experiencias.
Papert llevó las ideas de Piaget sobre la pedagogía constructivista un paso más allá al afirmar que los niños deberían construir algo para que puedan comprender mejor lo que queremos enseñarles. Su pedagogía construccionista sugiere que el aprendizaje debe ser un proceso creativo sin límites que dé como resultado un proyecto terminado que se pueda compartir con otros. Aunque era consciente de las limitaciones de Logo y la tortuga, Papert imaginó crear herramientas que permitieran a los niños aprender de manera más natural, como cuando alguien aprende francés viviendo en Francia en lugar de aprender el idioma en la escuela.
No enseñar matemáticas y arte por separado «Lo peor del currículo escolar es la fragmentación del conocimiento en pequeños fragmentos», argumentó Papert, antes de que Ken Robinson popularizara esta idea en sus charlas de TED vistas por cientos de millones. «Se supone que esto facilita el aprendizaje, pero a menudo termina privando al conocimiento de un significado personal y haciéndolo aburrido.
Pregúntele a algunos niños: la razón por la que a la mayoría no le gusta la escuela no es que el trabajo sea demasiado difícil, sino que es aburrido en extremo». Sus experimentos escolares revelaron que a los niños no les importaba trabajar duro en absoluto si el plan de estudios era atractivo. «Aprender es esencialmente difícil; sucede mejor cuando uno está profundamente comprometido en actividades difíciles y desafiantes. La comunidad de diseñadores de juegos ha entendido (para su gran beneficio) que esto no es motivo de preocupación.
De hecho, los niños prefieren cosas que son difíciles, siempre y cuando también sean interesantes. Papert reimaginó el aprendizaje como un proceso más orgánico: «los niños que aprenden a programar están aprendiendo ideas importantes sobre el movimiento, sobre la retroalimentación, están aprendiendo principios de diseño de ingeniería, sobre todo, están aprendiendo que el conocimiento es una cosa unificada, que el conocimiento científico y formal y matemático no es algo separado de su pasión por los juguetes, de las cosas que hicieron desde que eran niños pequeños».
Dar más libertad para explorar Es importante dejar volar la imaginación de los niños para que puedan experimentar las matemáticas como un matemático explorando nuevas ideas. Papert creía que deberíamos combinar la libertad que disfrutan los estudiantes en una clase de arte con la informática para incluir matemáticas e ingeniería.
Veía el aprendizaje como un proceso natural que a menudo se estropea por la coerción. En cambio, las escuelas deberían ser un lugar donde los niños tengan «permiso para pensar, soñar, mirar, obtener una nueva idea y probarla y abandonarla o persistir, tiempo para hablar, ver el trabajo de otras personas» y discutir las reacciones de los demás.
La educación debería involucrar a todos Papert, apodado ‘el inventor de todo lo bueno en educación’, estaba decidido a compartir sus descubrimientos de la manera más amplia posible. «Pocos académicos de la estatura de Papert han pasado tanto tiempo como él trabajando en escuelas reales. Se deleitaba en las teorías, ingenio y juego de los niños. Trabajar o programar con ellos fue la causa de muchas reuniones perdidas», recuerda uno de sus colegas. Puede haber comenzado experimentando con Logo y la tortuga mecánica en el MIT, pero luego los llevó a estudiantes que fueron dejados atrás por la sociedad.
Para muchos de nosotros, Seymour cambió fundamentalmente la forma en que pensamos sobre el aprendizaje, la forma en que pensamos sobre los niños y la forma en que pensamos sobre la tecnología, dice Mick Resnick, quien lidera el grupo de investigación Lifelong Kindergarten del Media Lab. Hoy en día, tenemos una gran cantidad de herramientas de tecnología educativa disponibles para integrar el construccionismo en el aula del siglo XXI. De hecho, nunca hemos estado tan cerca de hacer realidad las ideas de Papert. Solo una palabra de advertencia: el propósito de invertir en tecnología nueva y brillante debería ir más allá de mejorar los antiguos modelos de aprendizaje e introducir algo nuevo que beneficie a los niños y maestros, y a la sociedad en su conjunto.
Adetayo, A.J. (2023), «Artificial intelligence chatbots in academic libraries: the rise of ChatGPT«, Library Hi Tech News, Vol. 40 No. 3, pp. 18-21. https://doi.org/10.1108/LHTN-01-2023-0007
El estudio examina el surgimiento de los chatbots de inteligencia artificial en bibliotecas universitarias, centrándose específicamente en el desarrollo de ChatGPT. La investigación tiene como objetivo explorar las aplicaciones potenciales de esta tecnología en el ámbito académico, al tiempo que identifica los riesgos asociados. Para llevar a cabo esta evaluación, se realizó una revisión de la literatura utilizando fuentes de Google Scholar y revistas indexadas en la base de datos Scopus.
Los resultados del estudio indican que ChatGPT tiene el potencial de ser una herramienta útil para servicios técnicos y de lectores en bibliotecas universitarias. Puede ayudar en tareas como responder a consultas de referencia básicas, facilitar la navegación en el sitio web de la biblioteca y colaborar en investigaciones, catalogación, clasificación y desarrollo de colecciones. Sin embargo, el estudio también destaca preocupaciones importantes, como la posibilidad de respuestas inexactas a consultas, el riesgo de mal uso, la comprensión limitada, restricciones en la entrada de información y una dependencia excesiva de la tecnología.
Como conclusión, se sugiere que ChatGPT se utilice como una tecnología complementaria en lugar de un reemplazo para los bibliotecarios humanos en entornos académicos. Este artículo se presenta como uno de los primeros en abordar específicamente el potencial y los desafíos asociados con el uso de ChatGPT en bibliotecas universitarias
La inteligencia artificial generativa, que utiliza el aprendizaje automático para crear contenido en respuesta a indicaciones, ha suscitado preocupaciones sobre la deshonestidad académica en la educación. Aunque los temores de un fraude generalizado se han avivado, la investigación indica que el uso real con fines académicos deshonestos podría ser inferior a la percepción de los profesores. A pesar de esto, hay una creciente desconfianza entre los profesores, lo que lleva a acciones disciplinarias, afectando desproporcionadamente a ciertos grupos de estudiantes.
La inteligencia artificial generativa (Generative AI), que utiliza el aprendizaje automático para producir nuevo contenido (por ejemplo, texto o imágenes) en respuesta a indicaciones del usuario, se ha infiltrado en el sistema educativo y ha cambiado fundamentalmente las relaciones entre profesores y estudiantes.
En todo el país, los educadores han expresado niveles elevados de ansiedad sobre el uso de herramientas de Generative AI, como ChatGPT, por parte de los estudiantes para hacer trampa en tareas, exámenes y ensayos, además de temores de que los estudiantes pierdan habilidades críticas de pensamiento. Al respecto, un profesor incluso lo describió como algo que «ha infectado [el sistema educativo] como un escarabajo de la muerte, ahuecando estructuras sólidas desde adentro hasta su inminente colapso». En respuesta a estos temores, distritos escolares como Nueva York y Los Ángeles impusieron rápidamente prohibiciones para su uso tanto por parte de educadores como de estudiantes. Las escuelas recurrieron a herramientas como detectores de Generative AI para intentar restaurar el control y la confianza de los educadores; sin embargo, los esfuerzos de detección han sido insuficientes tanto en su implementación como en su eficacia.
Investigaciones del CDT confirman la disminución de la confianza…
Un hallazgo significativo a través de encuestas a profesores, padres y estudiantes es que la percepción de los profesores sobre el uso generalizado de Generative AI para hacer trampa parece ser en gran medida infundada. El 40% de los profesores que dicen que sus estudiantes han usado Generative AI para la escuela piensan que sus estudiantes lo han utilizado para escribir y enviar un ensayo. Pero solo el 19% de los estudiantes que informan haber usado Generative AI dicen que lo han utilizado para escribir y enviar un ensayo, un hallazgo respaldado por otras investigaciones de encuestas.
A pesar de la realidad de que una gran mayoría de estudiantes no utiliza Generative AI con fines académicos deshonestos, los profesores han desarrollado una mayor desconfianza en el trabajo de los estudiantes, quizás debido a la cobertura generalizada y aterradora de casos de trampa. El 62% de los profesores estuvo de acuerdo con la afirmación de que «[la] Generative AI me ha hecho más desconfiado sobre si el trabajo de mis estudiantes es realmente de ellos». Y esta desconfianza está afectando a ciertos grupos de estudiantes, que son disciplinados de manera desproporcionada por usar o ser acusados de usar Generative AI; los profesores de títulos I y los profesores de educación especial con licencia informan tasas más altas de acciones disciplinarias por el uso de Generative AI entre sus estudiantes.
Estos niveles elevados de desconfianza entre los profesores y las acciones disciplinarias subsiguientes han llevado a la frustración entre estudiantes y padres acerca de acusaciones erróneas de hacer trampa, lo que puede causar una brecha aún mayor entre profesores y estudiantes. Esta erosión de la confianza es potencialmente perjudicial para las comunidades escolares donde las relaciones sólidas entre educadores y estudiantes son imperativas para proporcionar un entorno de aprendizaje seguro y de calidad.
…Y herramientas de detección y capacitación insuficientes
Las herramientas diseñadas para detectar cuándo se usó Generative AI para producir contenido son actualmente las únicas soluciones tecnológicas disponibles para ayudar a los profesores a combatir la trampa basada en Generative AI; sin embargo, no resuelven los problemas de confianza existentes. En primer lugar, las políticas escolares sobre el uso de herramientas de detección de contenido son irregulares: solo el 17% de los profesores dicen que su escuela proporciona una herramienta de detección de contenido como parte de su plataforma tecnológica más amplia, y el 26% dice que su escuela recomienda su uso, pero deja a elección del educador elegir una e implementarla. Sin una guía sólida sobre el uso e implementación de las herramientas de detección de contenido, los profesores parecen dudar en utilizarlas como mecanismo de defensa contra la trampa. Solo el 38% de los profesores informan que usan una herramienta de detección de contenido de Generative AI con regularidad, y solo el 18% de los profesores están muy de acuerdo en que estas herramientas «son una forma precisa y efectiva de determinar si un estudiante está usando contenido generado por IA». La falta de confianza de los profesores está justificada, ya que, al menos en este momento, estas herramientas no son consistentemente efectivas para diferenciar entre texto generado por IA y escrito por humanos.
Además del uso de herramientas de detección, la confianza de los profesores en su propia eficacia para detectar la escritura creada por AI es baja: el 22% dice que son muy efectivos y el 43% dice que son algo efectivas. Esto es particularmente preocupante dado que la mayoría de los profesores no han recibido orientación sobre cómo detectar la trampa. Solo el 23% de los profesores que han recibido capacitación sobre las políticas y procedimientos de sus escuelas con respecto a Generative AI han recibido orientación sobre cómo detectar el uso de ChatGPT (u otra herramienta de Generative AI) cuando los estudiantes envían tareas escolares.
¿Cómo deberían abordar las escuelas la disminución de la confianza de los profesores?
Dadas nuestras investigaciones y lo que sabemos sobre las herramientas de detección de contenido de Generative AI, no son la respuesta, al menos por ahora. Estas herramientas sufren de problemas de precisión y pueden flagelar desproporcionadamente a los hablantes no nativos. En cambio, las escuelas deben:
Ofrecer capacitación a los profesores sobre cómo evaluar el trabajo de los estudiantes a la luz de la Generative AI: para ayudar a los profesores a sentir que tienen más control sobre la integridad académica en el aula, las escuelas deben capacitarlos adecuadamente para lidiar con la nueva realidad de la Generative AI. Esto implica proporcionarles capacitación sobre las limitaciones de los detectores y cómo responder si sospechan razonablemente que un estudiante está haciendo trampa.
Elaborar e implementar políticas claras sobre los usos permitidos y prohibidos: nuestras encuestas de este verano muestran que las escuelas no proporcionan orientación sobre lo que se define como «uso indebido» de la Generative AI, con un 37% de los profesores que informan que su escuela no tiene una política o no están seguros de si hay una política sobre Generative AI. Es imperativo que tanto los profesores como los estudiantes conozcan esto, para que todos estén en la misma página sobre el uso responsable de la Generative AI.
Alentar a los profesores a modificar las tareas para minimizar la efectividad de la Generative AI: comprender en qué no son buenas los sistemas de Generative AI puede ayudar a los profesores a diseñar tareas en las que el uso de Generative AI no sea útil para los estudiantes. Por ejemplo, los sistemas de Generative AI a menudo son ineficaces para proporcionar fuentes precisas para sus afirmaciones. Requerir que los estudiantes proporcionen citas para cualquier afirmación que hagan probablemente obligará a los estudiantes a ir mucho más allá de una respuesta generada.
McIlwain, J. Robertson. 2023. «Towards an Open Source-First Praxis in Libraries». Information Technology and Libraries 42 (4). https://doi.org/10.5860/ital.v42i4.16025.
En términos de utilidad y calidad técnica, las soluciones de software de código abierto se han convertido en una opción común para muchas bibliotecas. A medida que las barreras para la adopción se han reducido y sistemas como FOLIO parecen estar listos para cambiar el panorama de la tecnología de la información y la gestión de bibliotecas (LIS, por sus siglas en inglés), vale la pena examinar cómo el uso del código abierto puede respaldar los valores centrales normativos de la biblioteconomía y esbozar una estrategia para la participación crítica con la tecnología que beneficie a los usuarios y a las bibliotecas. Esa estrategia requerirá una mayor codificación, institucionalización e investigación del software de código abierto en muchos niveles.
El software de código abierto ha seguido ganando popularidad entre las bibliotecas en la última década. Ha pasado de ser algo periférico a convertirse en un competidor importante con algunos de los sistemas de software más establecidos en el sector de tecnología de bibliotecas. Sin embargo, la implementación ha sido desigual y todavía está representada en solo un pequeño porcentaje de bibliotecas. Entre aquellas que han adoptado sistemas de código abierto, el lenguaje utilizado para describir el cambio a menudo está relacionado más con el pragmatismo que con preocupaciones normativas. A medida que la aceptación del código abierto como una alternativa técnica legítima a los sistemas propietarios ha ganado impulso, algunos pueden estar interesados en reevaluar los impulsores hasta ahora utilitarios de la adopción de código abierto y preguntarse cómo puede fortalecer los valores e ideales de la biblioteconomía.
El movimiento de código abierto, aunque comparte algunos de los mismos ideales cívicos que la biblioteconomía, no es tan coherente motivacionalmente. Algunos sectores del movimiento están motivados por preocupaciones industriales o de mercado. Por lo tanto, a medida que el código abierto emerge como una opción común para muchas bibliotecas, es de interés para la profesión establecer, desde el principio, los términos en los que se involucrará críticamente con el código abierto.
A medida que el software ha madurado y el soporte de terceros se ha expandido, las barreras técnicas para adoptar el código abierto se han reducido considerablemente y, especialmente cuando se ve a través del prisma de la biblioteconomía crítica, las razones para elegir el código abierto son más pertinentes que nunca. Como se señaló, para muchas bibliotecas, la conversación hasta ahora se ha centrado, y no del todo injustamente, en gran medida en la utilidad y la rentabilidad (una vista desafortunadamente miope del software de código abierto que se detiene en la «utilidad potencial» y destaca la «facilidad de instalación»), ignorando cómo el código abierto puede respaldar los valores de la biblioteconomía y la misión de la biblioteca. Mientras que las preguntas sobre el personal de soporte y el presupuesto siguen siendo relevantes, los avances en la última década significan que ya no deben representar la totalidad de la discusión sobre el código abierto en las bibliotecas. Ahora las bibliotecas tienen la oportunidad de examinar cuál es, argumentablemente, la razón más fundamental por la que deberían adoptar una praxis de código abierto en primer lugar, un enfoque donde los sistemas propietarios de código cerrado solo deberían considerarse como último recurso.
La tecnología de código abierto presenta una oportunidad valiosa para las bibliotecas y los bibliotecarios para servir mejor a sus usuarios al respaldar los valores fundamentales de la profesión. Apoyar estos valores fundamentales es tanto pragmático (alineado con el valor fundamental del servicio) como moral-idealista (alineado con los valores fundamentales de la privacidad, equidad de acceso, custodia y libertad intelectual). Al mismo tiempo, es importante que los bibliotecarios evalúen críticamente y desafíen las suposiciones culturales en torno al estado actual del código abierto y las dinámicas de poder inherentes, y la información como una mercancía.
Las cinco leyes de la biblioteconomía Por Dianna Dilworth el 7 de julio de 2014 – 2:55 PM
INFOGRAFÍA
Las Cinco Leyes de Ranganathan
Los libros son para usarlos;
A cada lector su libro;
A cada libro su lector;
Ahorra el tiempo del lector;
La biblioteca es un organismo en crecimiento.
libraryinfographicUSC Online ha creado una infografía llamada, «Las Cinco Leyes de la Biblioteconomía», que explora cinco principios que pueden ayudar a guiar las prácticas de los bibliotecarios.
Según el gráfico, casi 2,5 millones de libros de bibliotecas públicas circularon entre más de 1,5 millones de personas en 2011. El gráfico también señala que hay más de 120.000 bibliotecas en Estados Unidos.
La publicación, una colaboración entre el gobierno, la academia y la industria, tiene la intención de ayudar a los desarrolladores y usuarios de IA a comprender los tipos de ataques que podrían esperar, junto con enfoques para mitigarlos, con la comprensión de que no hay una solución única.
Los sistemas de IA han permeado la sociedad moderna, trabajando en capacidades que van desde conducir vehículos hasta ayudar a los médicos a diagnosticar enfermedades o interactuar con clientes como chatbots en línea. Para aprender a realizar estas tareas, se entrenan con vastas cantidades de datos: un vehículo autónomo podría mostrar imágenes de carreteras con señales de tráfico, por ejemplo, mientras que un chatbot basado en un modelo de lenguaje grande (LLM) podría exponerse a registros de conversaciones en línea. Estos datos ayudan a la IA a predecir cómo responder en una situación dada.
Un problema importante es que los datos en sí mismos pueden no ser confiables. Sus fuentes pueden ser sitios web e interacciones con el público. Hay muchas oportunidades para que actores malintencionados corrompan estos datos, tanto durante el período de entrenamiento de un sistema de IA como después, mientras la IA continúa refinando sus comportamientos al interactuar con el mundo físico. Esto puede hacer que la IA se comporte de manera indeseable. Por ejemplo, los chatbots pueden aprender a responder con lenguaje abusivo o racista cuando se sortean cuidadosamente las protecciones mediante indicaciones maliciosas.
«En su mayor parte, los desarrolladores de software necesitan que más personas usen su producto para que pueda mejorar con la exposición», dijo Vassilev. «Pero no hay garantía de que la exposición sea buena. Un chatbot puede generar información negativa o tóxica cuando se le indica con un lenguaje cuidadosamente diseñado».
En parte porque los conjuntos de datos utilizados para entrenar una IA son demasiado grandes para que las personas los supervisen y filtren con éxito, todavía no hay una forma infalible de proteger la IA contra el desvío. Para ayudar a la comunidad de desarrolladores, el nuevo informe ofrece una visión de los tipos de ataques que podrían sufrir sus productos de IA y enfoques correspondientes para reducir el daño.
El informe considera los cuatro principales tipos de ataques: evasión, envenenamiento, privacidad y ataques de abuso. También los clasifica según múltiples criterios, como los objetivos y metas del atacante, las capacidades y el conocimiento.
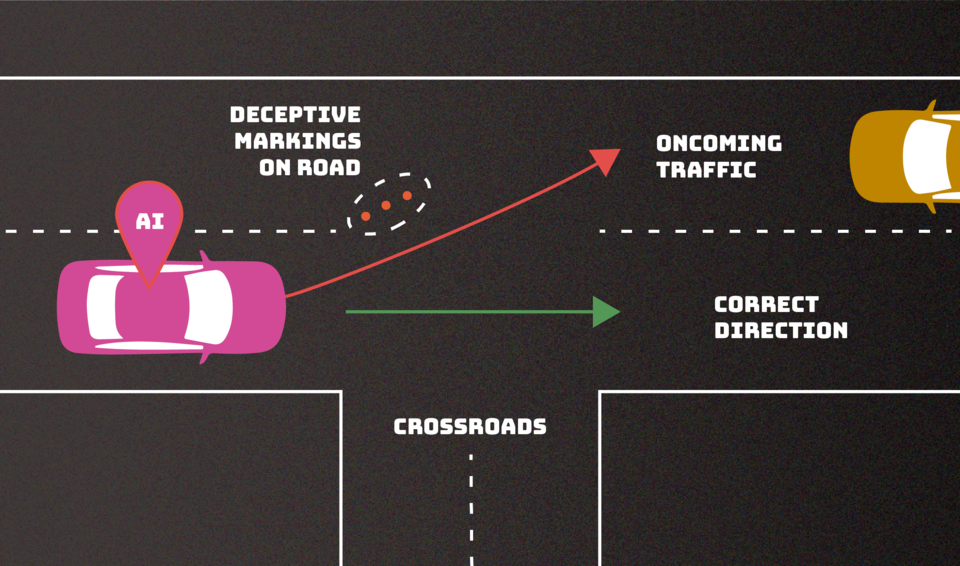
Los ataques de evasión, que ocurren después de que se implementa un sistema de IA, intentan alterar una entrada para cambiar cómo el sistema responde a ella. Ejemplos incluirían agregar marcas a señales de alto para hacer que un vehículo autónomo las interprete como señales de límite de velocidad o crear marcas de carril confusas para hacer que el vehículo se desvíe de la carretera.
Los ataques de envenenamiento ocurren en la fase de entrenamiento al introducir datos corruptos. Un ejemplo sería deslizar numerosas instancias de lenguaje inapropiado en registros de conversaciones, para que un chatbot interprete estas instancias como parloteo lo suficientemente común como para usarlo en sus propias interacciones con clientes.
Los ataques de privacidad, que ocurren durante la implementación, son intentos de aprender información sensible sobre la IA o los datos en los que se entrenó para mal usarla. Un adversario puede hacerle numerosas preguntas legítimas a un chatbot y luego utilizar las respuestas para ingeniería inversa del modelo para encontrar sus puntos débiles o adivinar sus fuentes. Agregar ejemplos indeseados a esas fuentes en línea podría hacer que la IA se comporte de manera inapropiada, y hacer que la IA olvide esos ejemplos específicos no deseados después del hecho puede ser difícil.
Los ataques de abuso implican la inserción de información incorrecta en una fuente, como una página web o un documento en línea, que una IA luego absorbe. A diferencia de los ataques de envenenamiento mencionados anteriormente, los ataques de abuso intentan darle a la IA piezas incorrectas de información de una fuente legítima pero comprometida para cambiar el uso previsto del sistema de IA.
«La mayoría de estos ataques son bastante fáciles de llevar a cabo y requieren un conocimiento mínimo del sistema de IA y capacidades adversarias limitadas», dijo la coautora Alina Oprea, profesora en la Universidad Northeastern. «Los ataques de envenenamiento, por ejemplo, pueden llevarse a cabo controlando unas pocas docenas de muestras de entrenamiento, lo que sería un porcentaje muy pequeño de todo el conjunto de entrenamiento».
Los autores, que también incluyeron a los investigadores de Robust Intelligence Inc., Alie Fordyce e Hyrum Anderson, desglosan cada una de estas clases de ataques en subcategorías y agregan enfoques para mitigarlos, aunque la publicación reconoce que las defensas que los expertos en IA han ideado contra ataques adversarios hasta ahora son incompletas.