Potkalitsky, Nick. 2025. “The Digital Detective Club: Teaching AI Literacy to Young Students.” Educating AI (blog), noviembre. https://nickpotkalitsky.substack.com/p/the-digital-detective-club-teaching
Vivimos un cambio profundo en la forma en que se crean los textos. Por primera vez en la historia, nuestros hijos crecerán en un mundo en el que gran parte de lo que leen —ayudas para deberes, explicaciones, historias e incluso mensajes “personales”— podría estar generado por inteligencia artificial (IA) en lugar de haber sido escrito por humanos. Esta realidad plantea un desafío educativo crucial: ¿cómo enseñar a los estudiantes a interactuar críticamente con la información que consumen desde edades tempranas?
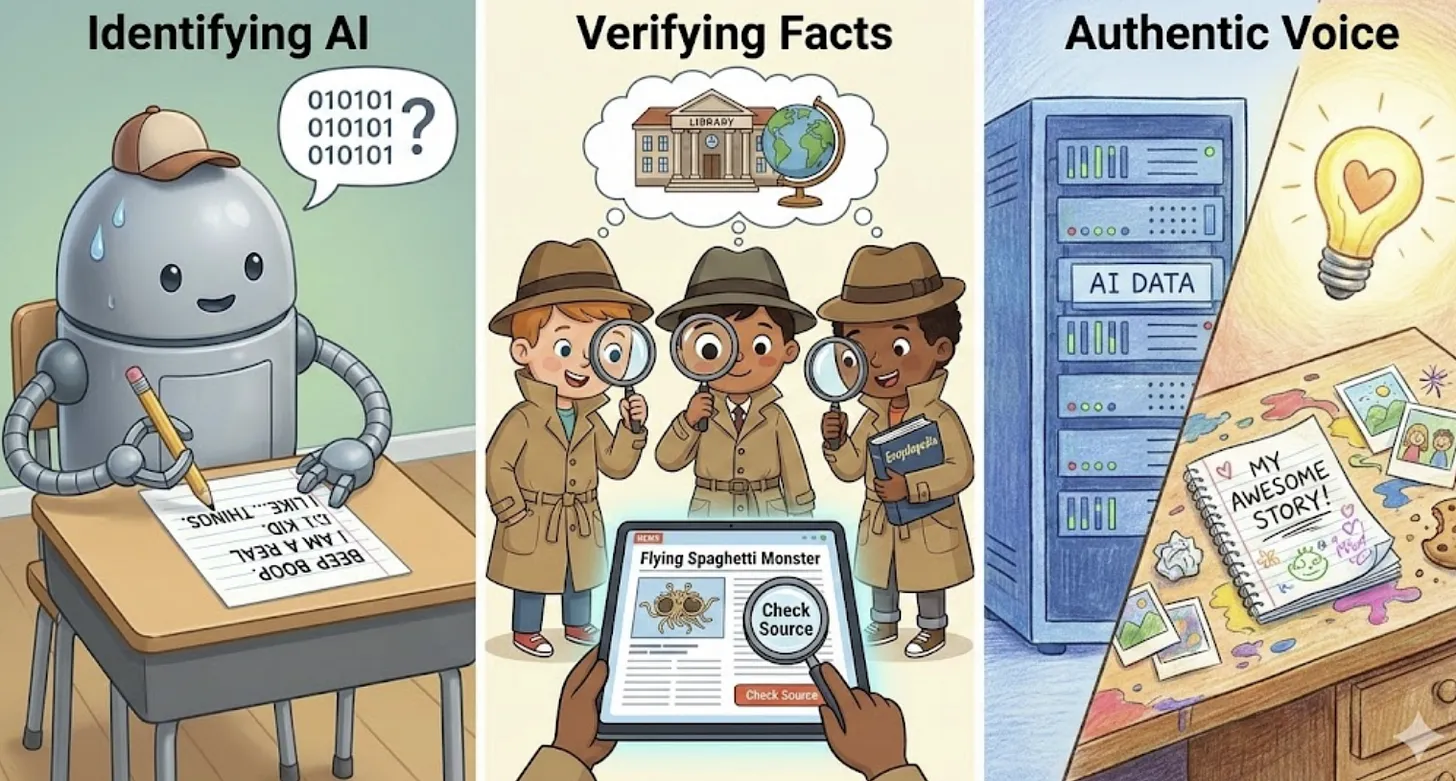
La mayoría de los programas de “alfabetización en IA” se enfocan en estudiantes mayores. Pero para cuando los alumnos llegan al bachillerato, ya han pasado años consumiendo contenidos generados por IA sin poseer herramientas para evaluarlos críticamente. Por ello se propone un plan de estudios dirigido a estudiantes de primaria (desde K hasta 5.º), que enseñe habilidades prácticas de “detección textual” para el mundo real en el que ya están inmersos.
Uno de los pilares del programa es la conciencia de la fuente. Los estudiantes aprenden a preguntarse no solo “¿es verdadero lo que leo?”, sino “¿de dónde viene?”, “¿quién lo escribió?” y “¿cómo puedo comprobarlo?”. De esta manera, desarrollan un hábito de verificación constante que los prepara para interactuar con contenidos digitales y automatizados de forma responsable.
Otro aspecto fundamental es el reconocimiento de la voz del texto. Los niños aprenden a diferenciar entre escritura humana y textos generados por IA, identificando rasgos como estilo, coherencia, singularidad o detalles personales que a menudo faltan en los textos automatizados. Esta habilidad les permite detectar cuándo un texto es genérico, neutro o artificial, y fomentar su pensamiento crítico.
El programa también enfatiza la valoración de la especificidad y lo concreto. Los alumnos comprenden que los textos valiosos, ya sean relatos, informes o explicaciones, incluyen detalles contextuales y matices propios. Por el contrario, los textos superficiales, impersonales o excesivamente generalizados pueden ser una señal de contenido automatizado o poco fiable. De esta forma, los estudiantes aprenden a apreciar la originalidad y a desarrollar criterios para discernir la calidad de la información.
Potkalitsky aclara que la intención no es asustar a los estudiantes ni alejarles de la IA, sino enseñarles a interactuar con ella de manera consciente, informada y responsable. La meta es que comprendan cuándo la IA puede ser útil y cuándo es necesaria la intervención humana para analizar, interpretar o tomar decisiones. Este enfoque contribuye a cultivar lo que el autor llama “conciencia situacional textual”: la capacidad de reconocer no solo qué leen los estudiantes, sino cómo, desde dónde, con qué intención y con qué propósito.
La alfabetización temprana en IA se vuelve especialmente relevante dado que muchos niños ya acceden a dispositivos, contenidos digitales y textos automatizados desde edades muy tempranas. Integrar estas competencias en la educación básica —en materias de lengua, lectura, ciudadanía digital y pensamiento crítico— permite preparar a los estudiantes para un entorno cada vez más mediado por la tecnología. Además, les proporciona herramientas para detectar desinformación, reconocer plagios, valorar la originalidad y mantener su propia voz creativa, habilidades fundamentales para desenvolverse con autonomía y responsabilidad en el mundo digital.
La propuesta busca transformar la manera en que los niños aprenden a leer, escribir y analizar información en la era de la inteligencia artificial. A través de ejercicios prácticos, análisis de textos y actividades lúdicas, los estudiantes desarrollan competencias críticas, creatividad y autonomía intelectual, preparándolos para enfrentar los desafíos educativos y sociales del siglo XXI.