Rismanchian, S., Razia Babar, E. T., & Doroudi, S. (2026). What undergraduate students need to know and actually know about generative AI. Computers and Education: Artificial Intelligence, artículo 100554. https://doi.org/10.1016/j.caeai.2026.100554
Este artículo analiza la alfabetización en inteligencia artificial generativa (GenAI) entre estudiantes de pregrado, un tema crítico dada la rápida adopción de herramientas como ChatGPT desde su lanzamiento en 2022.
Los autores proponen un marco teórico integral para evaluar la alfabetización en GenAI, que combina tres tipos de conocimiento conceptual: las bases de los modelos de lenguaje a gran escala (LLMs), sus capacidades y limitaciones, y su impacto social. Este marco se utiliza para desarrollar una encuesta validada que incluye ítems de conocimiento y percepciones, diseñada con revisión de expertos y modelado de teoría de respuesta al ítem (IRT) para asegurar su rigor metodológico.
Mediante dos estudios complementarios realizados en Estados Unidos —uno con estudiantes de cursos universitarios en una gran universidad pública de investigación (R1) y otro con una muestra nacional reclutada en línea— los autores investigan cuánto saben realmente los estudiantes sobre GenAI y cómo calibran sus percepciones sobre estas herramientas. Los resultados muestran que aproximadamente el 60% de los estudiantes usan chatbots de IA semanal o diariamente, pero muchos sobreestiman las capacidades de estos sistemas, especialmente en tareas que requieren razonamiento o cálculo, y tienden a antropomorfizarlos o tratarlos como simples motores de búsqueda.
Los hallazgos indican además que los estudiantes con formación en ciencias de la computación y aquellos que usan con mayor frecuencia estas herramientas obtienen puntajes de conocimiento más altos, aunque esto no garantiza una percepción exacta de sus capacidades. Un hallazgo clave es que un mayor conocimiento conceptual se asocia con una menor sobreestimación de las capacidades de los sistemas de IA generativa, lo que sugiere que las iniciativas educativas deben ir más allá del uso instrumental de las herramientas y abordar profundamente los conceptos fundamentales, las limitaciones técnicas y las implicaciones sociales de la IA.
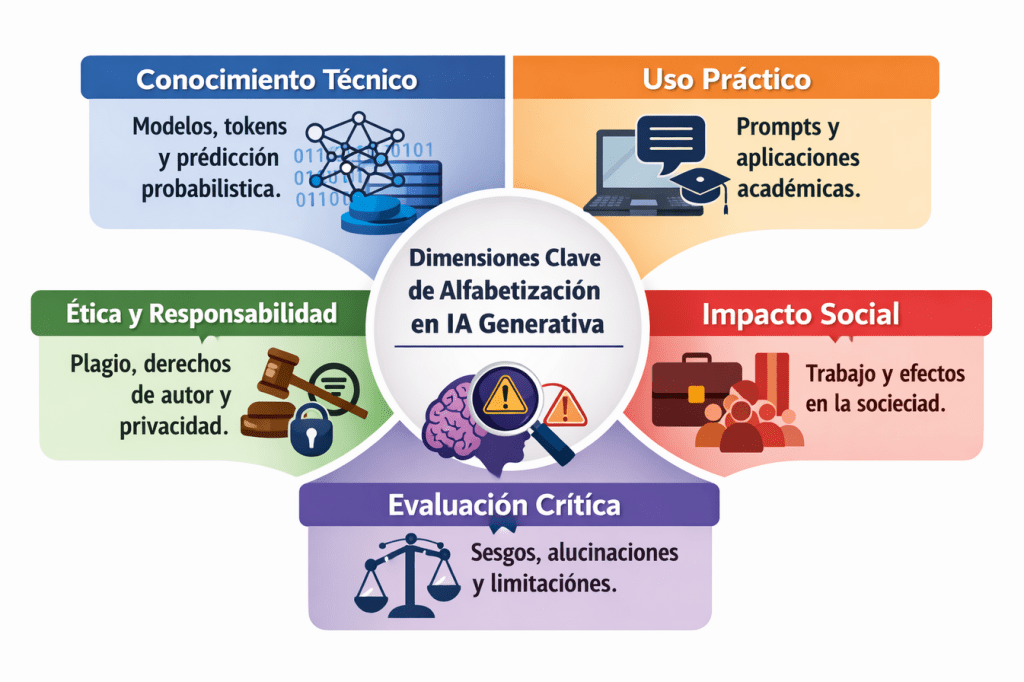
La investigación identifica 5 dimensiones clave de alfabetización en GenAI necesarias para un estudiante actual:
- Conocimiento Técnico: Cómo funcionan los modelos (tokens, predicción probabilística).
- Uso Práctico: Ingeniería de prompts y aplicaciones académicas.
- Evaluación Crítica: Identificar alucinaciones, sesgos y limitaciones.
- Ética y Responsabilidad: Plagio, derechos de autor y privacidad.
- Impacto Social: Cómo la IA afecta al mercado laboral y a la sociedad.