Gosal, Sachi, and Violet Boyd. «U-M Academics Say Rising Costs of Journal Subscriptions Are Hurting Scholarly Research.» The Michigan Daily, February 23, 2025. https://www.michigandaily.com/news/research/u-m-academics-say-rising-costs-of-journal-subscriptions-are-hurting-scholarly-research/
Académicos de la Universidad de Míchigan advierten que el aumento en los costos de suscripción a revistas académicas está afectando la investigación. Según la Asociación de Bibliotecas de Investigación, los precios de estas publicaciones han aumentado un 8,5 % anual entre 1986 y 2001, lo que dificulta el acceso a estudios fundamentales.
El aumento constante en los costos de suscripción y publicación de revistas académicas ha generado preocupaciones significativas en la comunidad investigadora, ya que estos incrementos pueden obstaculizar el acceso al conocimiento y limitar la difusión de nuevos hallazgos científicos.
Expertos como Cindy Lustig, profesora de psicología, señalan que los editores priorizan las ganancias sobre la accesibilidad. Además, investigadoras como Chloe Brookes temen que el incremento de costos genere un sesgo en la producción de conocimiento. Kara Zivin, profesora de psiquiatría en Salud Pública, advierte que los altos costos pueden desincentivar a jóvenes investigadores a publicar en revistas de acceso abierto.
Además, los cargos por procesamiento de artículos (APC, por sus siglas en inglés) en revistas de acceso abierto han alcanzado cifras elevadas. Por ejemplo, publicar en revistas de alto impacto puede costar hasta 10.000 euros por artículo, una cantidad que excede los costos reales de publicación y aumenta las ganancias de las grandes editoriales.
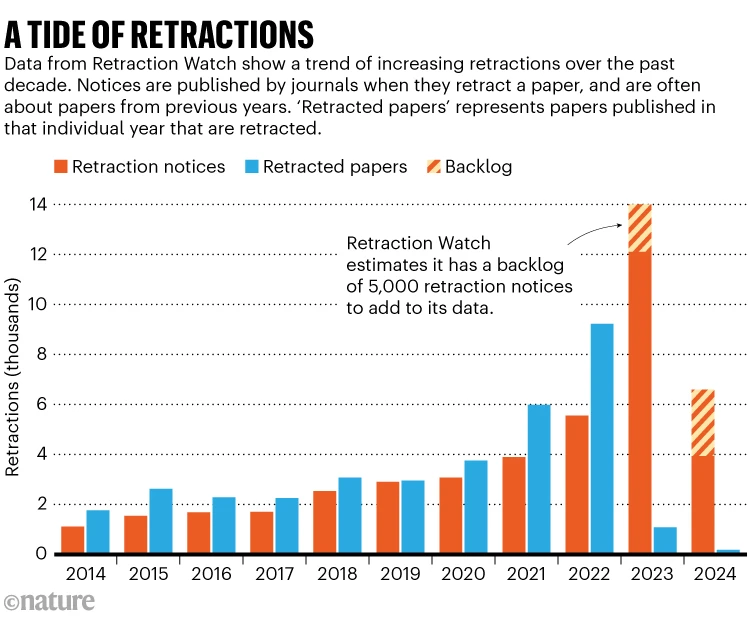
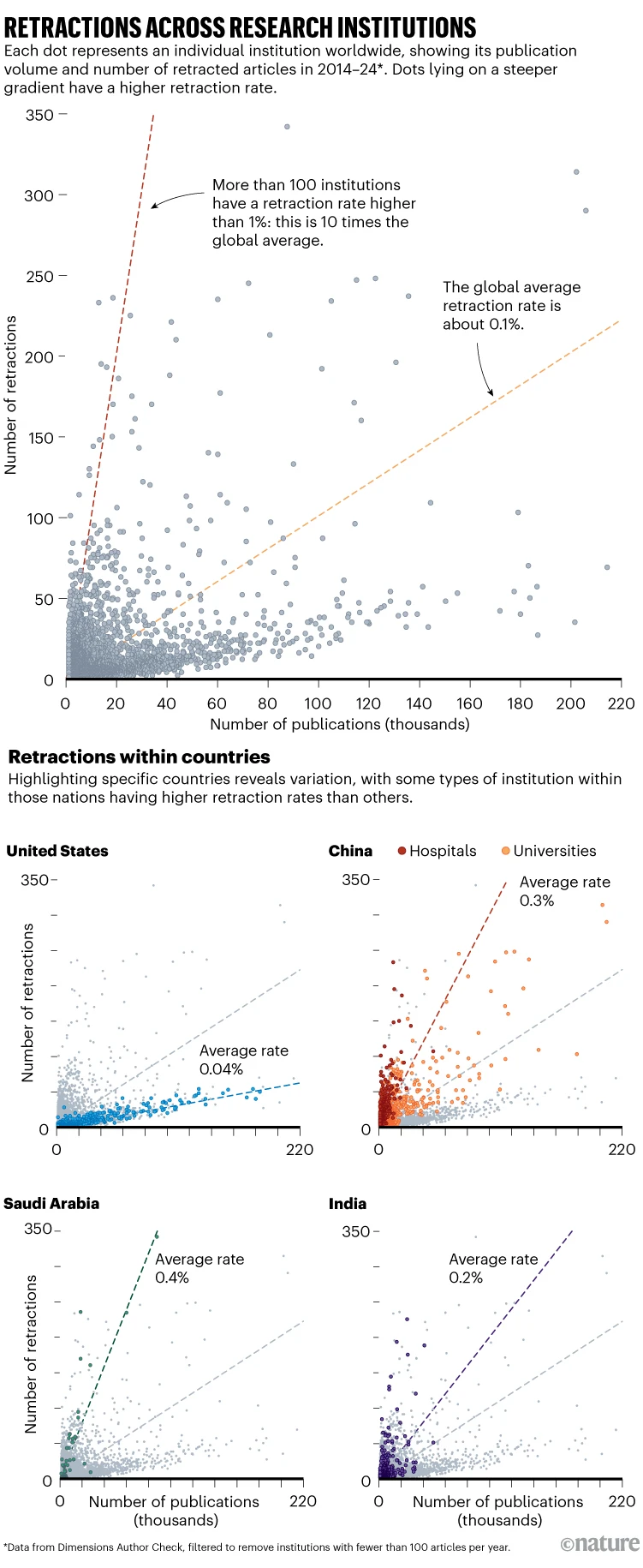
El aumento de los costos no solo afecta a las instituciones, sino que también tiene implicaciones directas en la diversidad y calidad de la investigación. Investigadores de países con menos recursos pueden enfrentar barreras financieras para publicar sus trabajos, lo que limita la representación de diversas perspectivas en la literatura científica. Además, la presión por publicar en revistas de alto impacto ha fomentado la proliferación de «revistas depredadoras» que, a cambio de una tarifa, publican artículos sin una revisión rigurosa, comprometiendo la calidad y credibilidad de la investigación científica
Ante este panorama, han surgido diversas iniciativas para contrarrestar los efectos negativos del modelo tradicional de publicación. El movimiento hacia el acceso abierto busca democratizar el acceso al conocimiento científico, permitiendo que los resultados de la investigación estén disponibles de manera gratuita para la comunidad global. Sin embargo, la transición hacia este modelo presenta desafíos, como la necesidad de financiamiento sostenible y la resistencia de algunas editoriales a modificar sus estructuras de negocio
La universidad ha implementado estrategias para mitigar estos efectos, como la alianza Big Ten Academic Alliance y el préstamo interbibliotecario. Sin embargo, Alan Piñon, director de comunicación de la biblioteca, advierte que, si los costos siguen subiendo, podrían reducirse las suscripciones a ciertos materiales. También resalta la importancia de preservar la información para futuras generaciones.