Se destaca que la gestión de referencias ha sido tradicionalmente percibida como una tarea tediosa; sin embargo, herramientas como EndNote, Zotero y Mendeley revolucionaron por completo este proceso, automatizando labores que antes eran manuales y laboriosas. En la actualidad, la evolución de estos gestores apunta hacia una nueva era impulsada por la inteligencia artificial (IA), en la que los flujos de trabajo se volverán más inteligentes, integrados y capaces de asistir al investigador de manera proactiva en todas las fases de su trabajo académico.
Gunn recorre la historia de estas herramientas, destacando el papel pionero de EndNote en los años 80 y 90 como software de escritorio y la posterior evolución hacia soluciones basadas en la web como Zotero y Mendeley. Estas últimas aprovecharon los metadatos uniformes, los DOIs y los navegadores web para permitir importaciones rápidas y precisas de referencias. Mendeley, en particular, introdujo elementos de interacción social, permitiendo a los investigadores compartir y descubrir trabajos entre pares, además de facilitar métricas alternativas basadas en la lectura y la colaboración académica.
La entrevista enfatiza que la próxima era de los gestores de referencias estará marcada por la integración de inteligencia artificial (IA) y flujos de trabajo más inteligentes. Según Gunn, los futuros gestores no solo almacenarán referencias, sino que ayudarán activamente a los investigadores a descubrir literatura relevante, comprender relaciones entre trabajos y generar citas correctas automáticamente, incluso adaptadas a distintos estilos bibliográficos. La IA también permitirá instrucciones específicas, como localizar el primer artículo que propuso una técnica determinada, agilizando la redacción y la revisión de literatura.
No obstante, Gunn advierte sobre las limitaciones de los modelos de IA: problemas de cobertura incompleta, sesgos en la recuperación de información y el riesgo de generar citas incorrectas o inexactas. Esto es especialmente crítico en revisiones sistemáticas o investigaciones que influyen en políticas, donde la supervisión humana sigue siendo imprescindible. Sin embargo, la IA puede automatizar tareas repetitivas, como extraer metodologías, resultados y métricas de estudios, liberando al investigador para centrarse en el análisis crítico y la síntesis de la información.
Otro aspecto abordado es la colaboración versus el trabajo individual. Si bien el análisis profundo sigue siendo una tarea humana, las fases de descubrimiento y organización de información se están volviendo cada vez más colaborativas. Herramientas que faciliten la cooperación entre equipos de investigación y comunidades académicas tendrán mayor relevancia, potenciando la eficiencia y la calidad de los procesos investigativos.
Finalmente, Gunn ofrece recomendaciones para desarrolladores de herramientas académicas: construir ventajas competitivas sólidas, comprender los flujos de trabajo reales de los investigadores y desarrollar estrategias claras para la adopción institucional. En conclusión, la nueva era de la gestión de referencias no busca reemplazar al investigador, sino apoyar cada etapa de su trabajo, integrando descubrimiento, organización, colaboración y análisis en flujos de trabajo más inteligentes y eficientes.
El informe MAHA, publicado en mayo de 2025 y encargado a la secretaria de Salud y Servicios Humanos, Robert F. Kennedy Jr., contenía numerosas referencias a estudios que no existían o eran fabricados, lo que sugiere que partes significativas del texto podrían haber sido generadas mediante prompts a sistemas de generative AI (IA generativa)
El informe Make America Healthy Again (MAHA), un documento emblemático publicado por la Comisión MAHA bajo la administración de Donald Trump, centrado en la salud infantil y en causas de enfermedad crónica en Estados Unidos. Una investigación del propio medio reveló originalmente que al menos siete citas incluidas en la versión inicial del informe simplemente no existían en la literatura científica —es decir, atribuían estudios que no estaban publicados o que jamás fueron escritos por los autores listados— lo que llevó a una fuerte preocupación por la integridad científica del texto.
Ante esta revelación, la Casa Blanca y el Departamento de Salud y Servicios Humanos (HHS) procedieron a reemplazar las citas inexistentes en una nueva versión del informe publicada en el sitio oficial de la Casa Blanca. Cinco de las referencias falsas fueron sustituidas por trabajos completamente distintos, y dos por estudios reales de los mismos autores mencionados previamente, aunque con títulos y contenidos distintos. Por ejemplo, un estudio epidemiológico supuestamente escrito por la investigadora Katherine Keyes fue reemplazado por un enlace a un artículo de KFF Health News sobre un tema similar, y otras referencias vinculadas a publicidad de medicamentos en niños se cambiaron por artículos periodísticos y estudios más antiguos sobre tendencias en uso de psicofármacos. Aunque estas nuevas fuentes parecen corresponder a estudios legítimos, no está claro si respaldan de manera precisa las afirmaciones formuladas en el informe original.
Además de sustituir las citas inexistentes, la versión actualizada también modificó referencias que habían sido mal interpretadas en la versión previa. Por ejemplo, un estudio que se usó para sostener que la psicoterapia es tan eficaz como los medicamentos en el corto plazo fue reemplazado después de que uno de los autores originales señalará a NOTUS que su investigación no incluía psicoterapia dentro de los parámetros analizados. A pesar de los cambios, tanto la Casa Blanca como funcionarios de HHS minimizaron la gravedad de los errores, describiéndolos como problemas menores de formato que ya habían sido corregidos, y defendieron la sustancia general del informe. Voceros oficiales declararon que el documento sigue siendo una evaluación histórica y transformadora para entender la epidemia de enfermedades crónicas que afectan a los niños estadounidenses, y subrayaron que los ajustes no alteran sus conclusiones principales.
Sin embargo, la actualización y corrección de citas ha suscitado debates profundos sobre los estándares de rigor científico que deben aplicarse a informes gubernamentales de salud pública, especialmente cuando estos documentos se utilizan para formular políticas importantes. Organizaciones periodísticas, científicos y legisladores han cuestionado la confiabilidad de las referencias del MAHA report y han pedido mayor transparencia en cómo se elaboran y revisan estos textos, así como sobre el uso de tecnologías como la inteligencia artificial durante su redacción. La situación ilustra las tensiones entre la comunicación científica, la integridad académica y las prioridades políticas en la producción de informes de política pública.
Ross Andersen aborda una crisis creciente en el mundo académico: el aluvión de investigaciones generadas con apoyo de inteligencia artificial que están saturando la producción científica con contenidos de baja calidad, irrelevantes o incluso falsos, lo que él denomina “AI slop” —una especie de desecho digital académico– que la comunidad científica aún no ha aprendido a gestionar eficazmente.
Cada día, en Bluesky y LinkedIn, Quintana veía a académicos publicar mensajes sobre el hallazgo de estas “citas fantasma” en artículos científicos. (La versión inicial del “Informe MAHA” de la administración Trump sobre la salud infantil, publicada la pasada primavera, contenía más de media docena de ellas). Pero hasta que Quintana encontró un falso artículo firmado por un “Quintana” citado en una revista para la que actuaba como revisor, había pensado que el problema se limitaba a publicaciones con estándares más bajos. “Cuando ocurre en una revista que respetas, te das cuenta de lo extendido que está el problema”.
Casi inmediatamente después de que los grandes modelos de lenguaje se popularizaran, los manuscritos comenzaron a llegar a las bandejas de entrada de las revistas en cantidades nunca vistas. Parte de este fenómeno puede atribuirse a la capacidad de la IA para aumentar la productividad, especialmente entre científicos no angloparlantes que necesitan ayuda para presentar su investigación. Pero ChatGPT y herramientas similares también se están utilizando para dar una nueva apariencia de plausibilidad a trabajos fraudulentos o chapuceros, según Mandy Hill, directora general de publicación académica en Cambridge University Press & Assessment. Esto hace que la tarea de separar el grano de la paja sea mucho más lenta para editores y revisores, y también más compleja desde el punto de vista técnico.
Andersen explica que la presión por publicar, combinada con la facilidad de generación de texto e incluso figuras mediante modelos de lenguaje avanzados, ha hecho que conferencias y revistas reciban enormes cantidades de trabajos que no aportan hallazgos verificables ni replicables, y que rara vez se someten a una revisión crítica profunda.
Este problema se agrava por la propia mecánica de la revisión por pares: muchos revisores están recurriendo también a herramientas de IA para evaluar artículos, y al mismo tiempo algunos autores insertan mensajes ocultos que incitan a estas IA a elogiar sus textos, lo que distorsiona aún más el proceso. Andersen describe casos concretos, como ilustraciones generadas que parecen plausibles pero son absurdas o científicamente incorrectas, y un incremento sin precedente en las presentaciones a conferencias de alto impacto en campos como el aprendizaje automático y la robótica. La IA también puede generar las imágenes de un artículo falso. Un artículo de revisión de 2024, ya retractado, publicado en Frontiers in Cell and Developmental Biology, incluía una ilustración generada por IA de una rata con unos testículos desproporcionadamente grandes y ridículos, que no solo superó la revisión por pares, sino que se publicó antes de que nadie lo advirtiera. Por embarazoso que fuera para la revista, el daño fue escaso. Mucho más preocupante es la capacidad de la IA generativa para crear imágenes convincentes de tejidos cortados en láminas finísimas, campos microscópicos o geles de electroforesis, que se usan habitualmente como pruebas en la investigación biomédica.
Las actas de congresos son el principal canal de publicación de artículos en IA y otras ciencias de la computación, y en los últimos años se han visto desbordadas por los envíos. NeurIPS, una de las principales conferencias de IA, ha visto duplicarse las presentaciones en cinco años. ICLR, la conferencia líder en aprendizaje profundo, también ha experimentado un aumento y parece incluir una cantidad considerable de slop: una startup de detección de LLM analizó los envíos para su próxima reunión en Brasil y encontró más de 50 que incluían citas alucinadas. La mayoría no se había detectado durante la revisión por pares. Eso podría deberse a que muchas de las revisiones por pares se realizaron con ayuda de la IA. Pangram Labs analizó recientemente miles de informes de revisión enviados a ICLR y descubrió que más de la mitad habían sido redactados con ayuda de un LLM, y alrededor de una quinta parte eran completamente generados por IA. En todas las ciencias académicas, los autores de artículos incluso han empezado a usar fuentes blancas diminutas para incrustar mensajes secretos dirigidos a los LLM revisores. Instan a las IA a elogiar el artículo que están leyendo, a describirlo como “revolucionario” y “transformador”, y a ahorrarles la molestia de una revisión exigente sugiriendo solo correcciones fáciles.
Este volumen ha superado la capacidad de revisión crítica de la comunidad, de modo que la investigación real y valiosa queda sepultada por un ruido cuya proporción crece constantemente. Además, el autor extiende el análisis a los servidores de preprints (sitios donde los científicos comparten borradores de sus trabajos antes de la revisión formal), donde la llegada masiva de textos asistidos por IA ha catalizado un incremento de publicaciones superficiales. Esto plantea un riesgo no solo para la credibilidad de estos repositorios, sino para todo el sistema de comunicación científica, que depende de un equilibrio entre cantidad y calidad para que los hallazgos genuinos puedan ser detectados, replicados y aprovechados. Expertos citados señalan que si este flujo no se frena, podría convertirse en una “crisis existencial” para ciertos campos del conocimiento, al difuminarse la distinción entre trabajo bien fundamentado y “slop” generado por algoritmos que simplemente repiten patrones sin entendimiento real. Hasta el punto de que ya se está hablando de una teoría conspirativa denominada “internet muerto”. Sus defensores creen que, en las redes sociales y otros espacios en línea, solo unas pocas personas reales crean publicaciones, comentarios e imágenes, y que el resto son generados y amplificados por redes de bots en competencia. Las IA escribirían la mayoría de los artículos y revisarían la mayoría de ellos. Este intercambio vacío serviría para entrenar nuevos modelos de IA. Imágenes fraudulentas y citas fantasma se incrustarían cada vez más profundamente en nuestros sistemas de conocimiento. Se convertirían en una contaminación epistemológica permanente que nunca podría filtrarse.
Torres-Salinas, D., & Arroyo-Machado, W. (2026). Las ‘Big Three’ de la información científica: Revisión bibliométrica comparativa de Web of Science, Scopus y OpenAlex (1.2.). InfluScience Ediciones. https://doi.org/10.5281/zenodo.18336510
El informe realiza un análisis exhaustivo de las tres principales bases de datos bibliográficas multidisciplinares que se utilizan en la evaluación de la investigación científica. Su objetivo central es ofrecer evidencia actualizada y crítica sobre cómo estas plataformas difieren en cobertura, calidad de metadatos, funcionalidades y utilidad estratégica para distintos tipos de análisis científico y de evaluación.
Este trabajo combina una revisión sistemática de la literatura reciente con un análisis bibliométrico original, lo que permite ofrecer tanto un marco teórico como datos empíricos recientes sobre estas bases de datos. En la primera parte, los autores presentan una revisión sistemática de estudios previos que comparan Web of Science, Scopus y OpenAlex. Se analizan aspectos como el volumen de registros, la cobertura de acceso abierto, la diversidad lingüística, la cobertura de referencias y la calidad de los metadatos. Esta revisión permite contextualizar la investigación actual y destacar las fortalezas y limitaciones de cada plataforma según la literatura existente. Además, se subraya la importancia de entender estos factores para tomar decisiones informadas en evaluaciones de producción científica y proyectos de bibliometría.
La segunda parte del informe desarrolla un análisis bibliométrico original, abarcando el período 2015–2024. Se examina la distribución longitudinal de los registros, los tipos documentales, los perfiles temáticos, las diferencias idiomáticas y los solapamientos entre las tres bases de datos. Los resultados muestran que OpenAlex tiene una cobertura total más amplia, incluyendo una mayor diversidad lingüística y un porcentaje mayor de contenido en acceso abierto, mientras que Web of Science y Scopus mantienen niveles más altos de consistencia y calidad de los metadatos. También se identifican diferencias en la proporción de tipos documentales y la granularidad en la clasificación temática.
Entre los hallazgos más relevantes, el informe destaca que las bases comerciales tradicionales operan con modelos de suscripción y curación estricta, lo que garantiza la fiabilidad de los datos, mientras que OpenAlex adopta un enfoque de acceso abierto y escalable, con ventajas en cobertura y representatividad geográfica. Asimismo, se observa que, aunque OpenAlex ofrece mayor amplitud, esto también implica mayores desafíos para la limpieza y consistencia de los registros. Estas diferencias son especialmente importantes para investigadores, bibliotecarios y gestores de ciencia que buscan equilibrar calidad y cobertura en estudios bibliométricos o evaluaciones institucionales.
Finalmente, los autores presentan un conjunto de recomendaciones estratégicas destinadas a optimizar la selección y el uso de estas bases de datos. Se sugiere combinar fuentes cuando se busque un balance entre calidad y amplitud, interpretar cuidadosamente los sesgos lingüísticos y geográficos, y elegir la plataforma según los objetivos específicos de cada análisis. El informe concluye resaltando que el conocimiento detallado de las características y limitaciones de Web of Science, Scopus y OpenAlex es esencial para garantizar evaluaciones científicas precisas, inclusivas y estratégicas.
El artículo de Retraction Watch expone un fenómeno descubierto en 2022 por el científico informático Guillaume Cabanac: ciertos trabajos científicos acumulaban un número inusualmente alto de citas en poco tiempo a pesar de haber sido descargados muy pocas veces, una discrepancia que no cuadraba con el impacto real del artículo.
Tras una investigación, Cabanac y sus colegas identificaron la causa en los metadatos enviados a Crossref, donde se incluían referencias que no aparecían ni en el PDF ni en la versión HTML del artículo, sino únicamente en los archivos técnicos que utilizan las bases de datos para indexar publicaciones.
El buscador marcó este artículo en particular —que ya ha sido retractado— por contener las llamadas frases manipuladas, giros extraños en términos establecidos que probablemente fueron introducidos por software de traducción o por personas que buscaban evadir los detectores de plagio.
Cabanac notó algo extraño: el estudio había sido citado 107 veces según el «donut de Altmetrics», un indicador del impacto potencial de un artículo, pero solo se había descargado 62 veces.
Además, según Google Académico, este artículo solo había sido citado una vez. “Había una clara discrepancia entre los recuentos de Google Académico y los de Altmetrics/Dimensions”, afirma Cabanac. Esta diferencia es especialmente significativa, ya que “sabemos que Google Académico suele sobreestimar el número de citas”, añade.
Este tipo de “citas invisibles” —citas añadidas en los metadatos pero no visibles para los lectores— acaba siendo procesado por servicios de métricas como Altmetrics o Dimensions, inflando artificialmente los contadores de citas y otras métricas de impacto académico. El artículo señala que esta manipulación perjudica la integridad de los sistemas de evaluación científica, pues métricas como el número de citas o índices derivadas de ellas se emplean a menudo para medir el rendimiento de investigadores y asignar financiación, lo que podría dar una imagen errónea del impacto real de ciertos autores o publicaciones.
Además, el reporte aclara que estas falsas referencias parecían proceder especialmente de ciertas revistas producidas por un editor específico, y que ni siquiera está claro si se trata de una manipulación deliberada o un fallo técnico de procesos de envío de metadatos. La situación pone de relieve la necesidad de mejorar los mecanismos de control de calidad en la producción de metadatos académicos y de desarrollar herramientas que comparen sistemáticamente las referencias visibles en el texto con las incluidas en los registros técnicos, para evitar que tales citaciones ocultas distorsionen las métricas científicas.
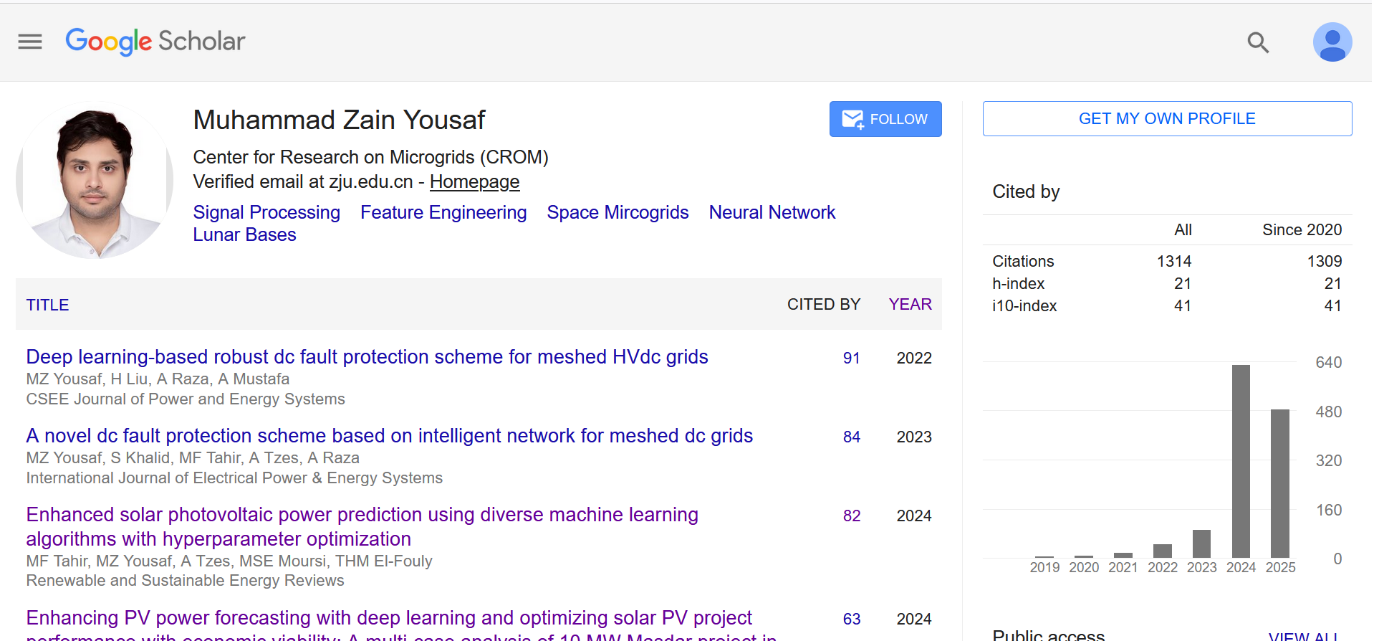
Un investigador logró inflar artificialmente su índice h en Google Scholar subiendo numerosos preprints cargados de autocitas, aprovechando que la plataforma indexa documentos sin revisión por pares.
Un investigador asociado a la Universidad de Zhejiang, Muhammad Zain Yousaf, logró un aumento extraordinario en su índice h de Google Scholar en un corto período de tiempo mediante una estrategia que aprovechó preprints cargados de autocitas. Según la investigación, Yousaf subió diez documentos a un servidor de preprints (TechRxiv) en solo dos días, y la mayoría de las referencias dentro de estos documentos eran trabajos propios, en muchos casos con el autor repitiéndose en una proporción muy alta de la bibliografía. Esto provocó que su índice h, una medida de productividad y impacto científico que combina publicaciones y citaciones, se disparara a niveles comparables a los de académicos sénior, aunque la calidad real de los documentos era cuestionada por expertos que los describieron como incoherentes o de baja calidad técnica.
La situación generó sospechas de manipulación de métricas académicas, ya que Google Scholar indexa automáticamente citas incluso de fuentes sin revisión por pares, lo que permite que documentos no evaluados formalmente influyan en el cómputo de indicadores bibliométricos. Investigadores que analizaron el caso descubrieron que, al excluir autocitas y fuentes sin revisión formal (como preprints y actas de conferencias), el índice h real de Yousaf se reducía a la mitad o más, lo que pone en evidencia la fragilidad del sistema para medir el impacto científico auténtico frente a maniobras de este tipo.
El informe también pone énfasis en que esta no es una anomalía única: otros casos documentados muestran que Google Scholar puede ser sencillo de manipular debido a la forma en que indexa contenido en línea, lo que plantea preocupaciones sobre su uso generalizado para evaluaciones académicas, contrataciones y financiación. Expertos citados en el artículo señalan que, mientras continúe la presión sobre investigadores para obtener altas métricas de citación, seguirán apareciendo tácticas similares que explotan lagunas en los sistemas de evaluación automatizados.
Consensus, una herramienta de búsqueda académica basada en inteligencia artificial, puede integrarse de forma sencilla con distintos gestores de referencias bibliográficas como EndNote, Zotero o Paperpile.
El objetivo principal de esta integración es facilitar el trabajo investigador, permitiendo que las referencias encontradas en Consensus se incorporen directamente a los sistemas habituales de gestión bibliográfica, evitando así la introducción manual de datos y reduciendo errores en la citación.
Consensus permite exportar los resultados de búsqueda y las listas de artículos guardados en formatos estándar ampliamente aceptados en el ámbito académico, principalmente RIS y CSV. Estos formatos son compatibles no solo con EndNote, Zotero y Paperpile, sino también con otros gestores como Mendeley, RefWorks, Citavi o Papers. De este modo, el investigador puede transferir rápidamente la información bibliográfica —autores, títulos, revistas, fechas y otros metadatos— a su gestor de referencias preferido y continuar allí el proceso de organización, anotación y citación.
El proceso de exportación es sencillo: tras realizar una búsqueda en Consensus o acceder a una lista previamente guardada, basta con utilizar la opción de descarga y seleccionar el formato deseado. En el caso de Zotero, además, se destaca la utilidad del Zotero Connector, una extensión de navegador que permite guardar directamente los artículos desde la página de resultados o desde la ficha individual de cada trabajo, integrando así Consensus en el flujo de trabajo habitual del investigador de forma casi inmediata.
El objetivo del informe es explorar cómo las organizaciones del ámbito de la publicación académica están adoptando y respondiendo a la inteligencia artificial (IA). La encuesta, realizada entre el 1 y el 12 de diciembre de 2025 entre 563 profesionales de distintas organizaciones, revela que la IA ya está muy presente en los flujos de trabajo de la publicación académica, aplicándose principalmente en tareas relacionadas con la creación y resumen de contenidos, revisión de integridad y detección de plagio, así como en herramientas de accesibilidad y descubrimiento de contenidos.
A pesar de esta adopción generalizada, el informe subraya que la preparación institucional para gestionar el impacto de la IA sigue rezagada respecto al uso tecnológico. La mayoría de las organizaciones se encuentran en un estado de preparación parcial, con políticas, capacidades y conocimientos aún en desarrollo, lo que refleja que el entusiasmo por la IA va acompañado de incertidumbre y retos organizativos. Entre los principales obstáculos se encuentran preocupaciones éticas y legales, problemas de privacidad y seguridad de datos, y una insuficiente capacidad especializada dentro de los equipos.
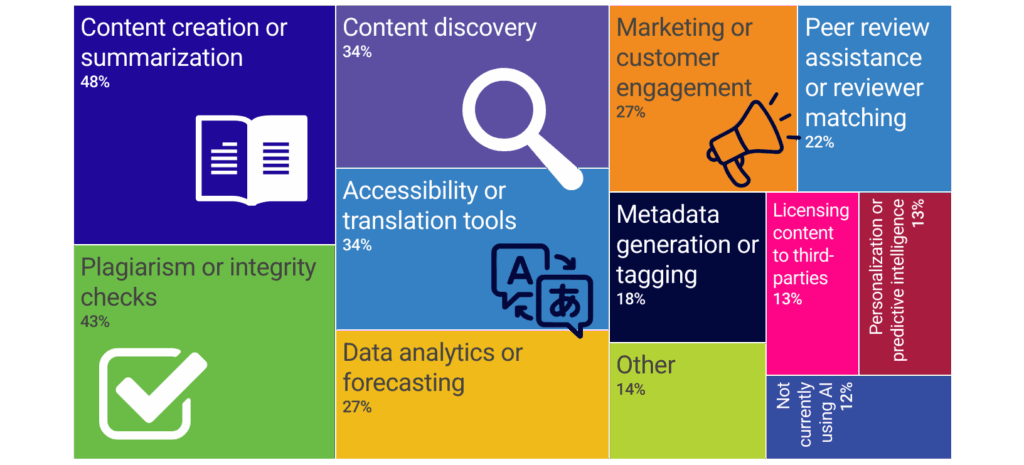
Las respuestas a la encuesta muestran que la adopción de IA ya está en marcha en las organizaciones de publicación académica, y la gran mayoría reporta al menos un caso de uso activo. Las aplicaciones más comunes se centran en los flujos de trabajo relacionados con el contenido, particularmente la creación o resumen de contenido (48%) y la verificación de plagio o integridad de la investigación (43%). Estos usos reflejan áreas donde la IA puede ofrecer ganancias inmediatas de eficiencia y ampliar el soporte a los procesos editoriales existentes sin alterar fundamentalmente la autoridad en la toma de decisiones.
Las herramientas de accesibilidad y traducción (34%) y el descubrimiento de contenido (34%) también son muy relevantes, subrayando el papel creciente de la IA en mejorar el alcance, la usabilidad y la encontrabilidad del contenido académico.
Más allá de las funciones editoriales principales, las organizaciones aplican cada vez más la IA a actividades empresariales y operativas. Más de una cuarta parte de los encuestados informa que utiliza IA para marketing o interacción con clientes (27%) y para análisis de datos o previsiones (27%), lo que indica una mayor comodidad con los conocimientos generados por IA para informar estrategias y alcance de la audiencia. La asistencia en la revisión por pares o la asignación de revisores (22%) y la generación o etiquetado de metadatos (18%) aparecen como aplicaciones emergentes, pero aún no universales, lo que sugiere tanto oportunidad como cautela en áreas que interfieren más directamente con el juicio académico y el control de calidad.
De acuerdo con los datos mostrados, las categorías con mayor peso son:
Creación o resumen de contenido: Es la aplicación más destacada con un 48%.
Controles de plagio o integridad: Ocupa el segundo lugar con un 43%.
Descubrimiento de contenido: Representa un 34%.
Herramientas de accesibilidad o traducción: Empata con el descubrimiento de contenido con un 34%.
Marketing o compromiso del cliente: 27%.
Análisis de datos o pronósticos: 27%.
Asistencia en revisión por pares o emparejamiento de revisores: 22%.
Generación de metadatos o etiquetado: 18%.
Licencia de contenido a terceros: 13%.
Personalización o inteligencia predictiva: 13%.
Finalmente, la imagen indica que un 14% corresponde a otros usos y un 12% de los consultados no utiliza IA actualmente.
Actitudes hacia la IA
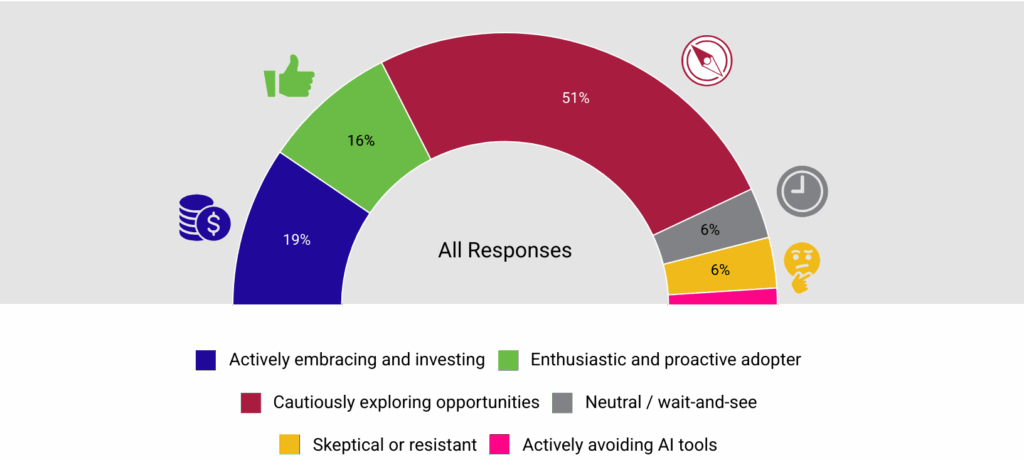
Las respuestas indican que la mayoría de las organizaciones abordan la IA con interés medido, más que con entusiasmo incondicional. La mayoría (51%) describe su postura como exploración cautelosa de oportunidades, lo que sugiere experimentación activa junto con consideración cuidadosa de riesgos, gobernanza y adecuación. Al mismo tiempo, más de un tercio de los encuestados muestra una postura fuertemente positiva hacia la IA: 19% adopta activamente e invierte en IA y 16% se identifica como adoptante entusiasta y proactivo — juntos indican un impulso significativo hacia una integración más profunda.
Solo una pequeña minoría permanece al margen o en contra. Solo el 6% reporta una postura neutral de esperar y ver, otro 6% se declara escéptico o resistente, y solo 2% evita activamente las herramientas de IA. En conjunto, estos resultados sugieren que, aunque la cautela sigue siendo dominante, la resistencia a la IA en la publicación académica es limitada y la trayectoria general apunta hacia una adopción más amplia con el tiempo.
Preparación ante la IA
Las respuestas sugieren que la mayoría de las organizaciones se sienten parcialmente preparadas para enfrentar el impacto de la IA en el próximo año. Casi la mitad (45%) reporta estar moderadamente preparada, mientras otro 27% se siente solo ligeramente preparada, lo que indica que muchas organizaciones todavía están construyendo habilidades, políticas y confianza interna. Un porcentaje menor se siente altamente preparado: 16% se describe como muy preparado y solo 3% como completamente preparado, lo que subraya lo rara que sigue siendo la sensación de preparación total. Al mismo tiempo, 9% reporta no estar preparado en absoluto, destacando la necesidad de orientación, buenas prácticas compartidas y desarrollo de capacidades en toda la comunidad.
El sondeo también identifica oportunidades importantes asociadas con la IA, entre ellas la eficiencia de los flujos de trabajo —que puede liberar tiempo para tareas de mayor valor añadido—, el fortalecimiento de la revisión por pares mediante herramientas de apoyo o asignación de revisores, y el uso de IA para reforzar la integridad y calidad de la investigación a través de la detección de plagio o de prácticas poco éticas. Asimismo, la IA se percibe como una herramienta valiosa para mejorar la descubribilidad del contenido científico y para apoyar a autores de distintas lenguas mediante traducción y servicios lingüísticos.
Barreras para la adopción de IA
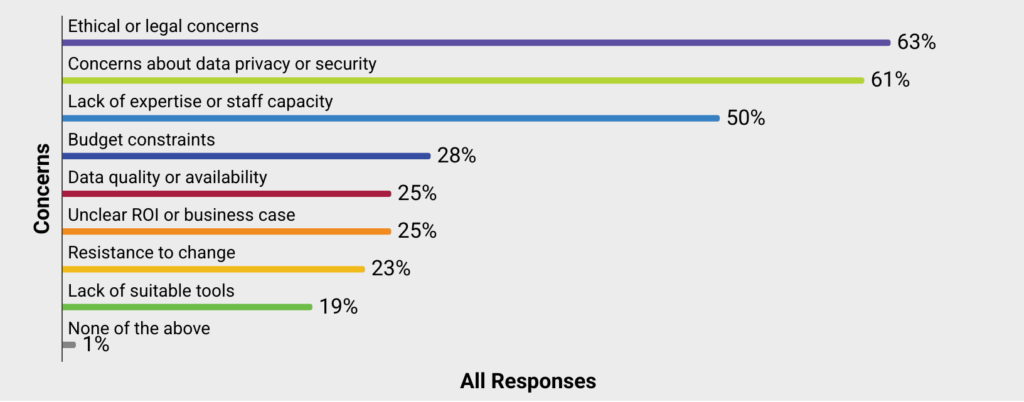
Los encuestados identificaron preocupaciones legales/éticas, privacidad/seguridad y falta de experiencia/capacidad como las principales barreras para la adopción de IA.
A pesar de los altos niveles de adopción e interés en IA, las organizaciones de publicación académica todavía albergan serias preocupaciones sobre su uso en el sector. Las preocupaciones éticas o legales (63%) y los problemas de privacidad o seguridad de los datos (61%) encabezan la lista, reflejando cautela generalizada respecto a cumplimiento, propiedad intelectual y uso responsable — preocupaciones especialmente agudas en la publicación académica. La preparación organizacional también emerge como un desafío significativo, con la mitad de los encuestados (50%) citando la falta de experiencia o capacidad del personal, lo que subraya que las capacidades humanas e institucionales a menudo quedan detrás del interés tecnológico.
Consideraciones prácticas y financieras forman un segundo nivel de barreras. Restricciones presupuestarias (28%), calidad o disponibilidad de datos (25%) y un ROI o caso de negocio poco claros (25%) sugieren que muchas organizaciones todavía evalúan costos frente a beneficios inciertos. Los problemas culturales y de herramientas —como la resistencia al cambio (23%) y la falta de herramientas adecuadas (19%)— son menos dominantes pero todavía significativos. Casi todas las organizaciones reportan algún tipo de fricción al adoptar IA.
No obstante, las preocupaciones sobre los riesgos son profundas y existenciales. Muchos encuestados expresan inquietudes sobre la posibilidad de que la IA degrade la calidad y la integridad de la literatura académica, dificultando la detección de contenidos generados por IA sin rigor científico, y erosionando la confianza en el proceso de revisión por pares tradicional. También existe ansiedad sobre la falta de transparencia en el uso de IA y la autenticidad de las contribuciones cuando las herramientas automatizadas participan en la producción o evaluación de trabajos. En conjunto, estas respuestas reflejan una comunidad editorial que navega entre la oportunidad de mejorar procesos y la necesidad de proteger los valores fundamentales de la comunicación científica.
Higher Education Policy Institute (HEPI) & Taylor & Francis (8 de enero de 2026). Using Artificial Intelligence (AI) to Advance Translational Research (HEPI Policy Note 67). Disponible en HEPI Insights
El informe analiza de manera exhaustiva cómo la inteligencia artificial puede transformar el proceso de investigación académica para acelerar su impacto en el mundo real, especialmente en lo que se conoce como investigación traslacional, es decir, la que busca convertir descubrimientos científicos en aplicaciones prácticas y beneficios tangibles para la sociedad.
Un nuevo informe elaborado por HEPI y Taylor & Francis explora el potencial de la inteligencia artificial (IA) para impulsar la investigación traslacional y acelerar el camino que va desde el descubrimiento científico hasta su aplicación práctica en la sociedad.
Using Artificial Intelligence (AI) to Advance Translational Research (Nota de política HEPI n.º 67), elaborado por Rose Stephenson, directora de Política y Estrategia de HEPI, y Lan Murdock, directora sénior de Comunicación Corporativa en Taylor & Francis, se basa en los debates mantenidos en una mesa redonda con responsables del ámbito de la educación superior, investigadores, innovadores en IA y organismos financiadores, así como en una serie de estudios de caso de investigación, para evaluar el papel futuro de la IA en la investigación traslacional.
Principales conclusiones
El informe concluye que la IA tiene el potencial de reforzar el sistema de investigación traslacional del Reino Unido, pero que la materialización de estos beneficios requerirá una implementación cuidadosa, una gobernanza adecuada y una inversión sostenida.
Entre las principales conclusiones se incluyen las siguientes:
La IA podría acelerar la investigación traslacional al permitir un análisis más rápido de grandes y complejos conjuntos de datos, apoyar la síntesis del conocimiento y mejorar los vínculos entre disciplinas. Sin embargo, la disponibilidad y la calidad de estos conjuntos de datos siguen siendo desiguales, lo que limita en algunos ámbitos la capacidad de las herramientas de IA para apoyar la traducción de la investigación.
El acceso a competencias y experiencia en IA es cada vez más importante, y la integración de estas capacidades en marcos interdisciplinarios será un componente clave para impulsar la investigación traslacional.
La IA puede mejorar la accesibilidad y la visibilidad de la investigación, entre otras cosas mediante resúmenes en lenguaje claro, sistemas de búsqueda semántica (funciones de búsqueda que utilizan conceptos e ideas, y no solo palabras clave, ofreciendo resultados más precisos) y nuevos formatos dirigidos a públicos más allá del ámbito académico.
Existen riesgos claros asociados al uso de la IA, incluidos los desafíos relacionados con la reproducibilidad, los sesgos, la pérdida de competencias, la integridad académica, la propiedad intelectual y la rendición de cuentas.
Recomendaciones
Para garantizar que la IA respalde una investigación traslacional de alta calidad y realizada de manera responsable, el informe formula una serie de recomendaciones dirigidas a organismos financiadores de la investigación, instituciones y editoriales, entre las que se incluyen:
Establecer expectativas claras para el uso responsable de la IA, incluida su alineación con orientaciones como Embracing AI with Integrity de la UK Research Integrity Office.
Invertir en una IA fiable y ética, incluyendo acciones para mejorar la transparencia, reducir los sesgos y apoyar la reproducibilidad.
Reforzar el apoyo a la investigación interdisciplinaria, con un mayor reconocimiento del trabajo en equipo y vías más claras para acceder a conocimientos y experiencia en IA.
Apoyar infraestructuras compartidas y abiertas de investigación en IA para reducir duplicidades y facilitar que las herramientas desarrolladas por investigadores estén disponibles de forma más amplia.
Fomentar el intercambio y la reutilización de datos, junto con la inversión en infraestructuras que permitan un acceso seguro y responsable a los datos.
Rose Stephenson, directora de Política y Estrategia de HEPI y coautora del informe, afirmó: «El Reino Unido cuenta con fortalezas extraordinarias en investigación, pero demasiadas ideas tienen dificultades para recorrer el camino desde el descubrimiento hasta su uso en el mundo real. La IA tiene el potencial de apoyar este proceso acelerando el análisis, conectando disciplinas y mejorando el acceso a la investigación. Sin embargo, estos beneficios solo se harán realidad si la IA se utiliza de manera transparente, ética y de formas que refuercen, en lugar de sustituir, la experiencia humana».
Por su parte, Rebecca Lawrence, vicepresidenta de Traducción del Conocimiento en Taylor & Francis, señaló: «Estamos muy agradecidos a todos los participantes de la mesa redonda y a quienes compartieron aportaciones para los estudios de caso. Los valiosos debates y el proceso posterior de elaboración de la nota de política han puesto de relieve los beneficios de trabajar de manera colectiva para aprovechar el poder y las oportunidades que puede ofrecer el uso responsable de la IA en la investigación traslacional».
Mediante la inversión en conocimiento interdisciplinario, gobernanza ética e infraestructuras, las partes interesadas pueden contribuir a transformar la investigación traslacional y permitir que un mayor número de investigaciones recientes genere beneficios sociales significativos.
A finales de 2025 empezaron a surgir informes sobre algo que han llamado revistas imaginarias. La IA generativa puede “alucinar”, es decir, inventar hechos o datos presentándolos como reales, pero que llegue al punto de generar títulos de revistas y citas que no existen en absoluto ha sorprendido a muchos.
Se han detectado referencias a publicaciones que nunca han existido en trabajos académicos. Estamos acostumbrados a las revistas falsas o depredadoras, pero estos nuevos títulos sólo aparecen en bibliografías generadas por IA, sin rastro real de su existencia.
Además, también se han encontrado artículos atribuidos a autores que no existen. Incluso algunos de estos textos se han presentado a revistas legítimas. Esto podría formar parte de pruebas para evaluar sistemas de revisión o detección de plagio, aunque también podría responder a fines más oscuros.
Aunque suene sorprendente, la aparición de artículos completamente generados por IA está alterando las normas tradicionales de la investigación y la publicación académica. Muchos repositorios de preprints han tenido que restringir envíos ante el aumento de trabajos de baja calidad generados por IA.
El impacto podría ser serio: si se difunden investigaciones inventadas y otros investigadores las citan o usan como referencia, el daño se propaga rápidamente. Incluso se han visto casos en los que artículos falsos han sido citados decenas de veces, sin que los autores supieran que su nombre aparecía en esos documentos.
Frente a esta situación, las fuentes verificadas de publicaciones científicas se vuelven más importantes a medida que el uso de IA se expande. Las fronteras entre investigación humana, híbrida o generada exclusivamente por IA se están desdibujando, con implicaciones profundas para editores, autores, instituciones y financiadores.