Las bibliotecas públicas en Estados Unidos están transformando su rol tradicional de prestadoras de materiales hacia funciones más amplias como centros comunitarios que promueven la inclusión social, la educación nutricional y la seguridad alimentaria.
Las bibliotecas, espacios reconocidos por su accesibilidad y confianza social, están aprovechando la comida como un vehículo para construir comunidad y responder a necesidades reales de la población. En lugar de limitarse a prestar libros, muchas están ofreciendo clases prácticas de cocina, talleres de alfabetización nutricional y educación sobre seguridad alimentaria, permitiendo a personas de distintas edades y orígenes aprender habilidades culinarias, reducir el desperdicio de alimentos y compartir experiencias en espacios seguros y abiertos.
El texto destaca ejemplos concretos, como el Free Library of Philadelphia Culinary Literacy Center, que ofrece más de 30 programas mensuales, desde clases con chefs locales hasta cursos de alfabetización en inglés basados en la cocina, demostrando cómo estos programas enriquecen tanto la competencia técnica como la cohesión social. Asimismo, iniciativas como los programas de cocina para jóvenes o despensas comunitarias han permitido a las bibliotecas adaptarse a las necesidades específicas de sus comunidades, combatiendo el aislamiento social, promoviendo hábitos alimentarios saludables y fomentando la asistencia física a las bibliotecas, que en años recientes había disminuido considerablemente.
Además de sus beneficios educativos y sociales, el artículo alerta sobre los riesgos derivados de recortes presupuestarios a programas de apoyo alimentario y a fondos para bibliotecas, que podrían limitar la continuidad de estas iniciativas, especialmente en áreas vulnerables. Esto evidencia la importancia de financiación estable y política pública que respalde el papel multifuncional de las bibliotecas como espacios que no solo promueven el acceso a la información, sino también el bienestar integral de sus comunidades.
El texto aborda la creciente presencia de la inteligencia artificial en el ámbito de la educación superior y, en particular, en las bibliotecas académicas, subrayando la necesidad de reflexionar sobre sus implicaciones éticas.
La Inteligencia Artificial (IA) se ha integrado cada vez más en casi todas las facetas de la vida, lo que plantea numerosos problemas éticos urgentes en relación con su diseño y uso, así como sus impactos en la sociedad y el medio ambiente. Si bien la IA, el campo científico dedicado a crear sistemas que puedan igualar el rendimiento humano (realizar acciones que un ser humano puede realizar), existe desde la década de 1950, el lanzamiento público de la herramienta de IA generativa ChatGPT en noviembre de 2022 y su comercialización acelerada desde entonces la han situado en el centro de la concienciación y la preocupación pública.
Dada su capacidad para generar contenido que antes solo se creaba mediante la inteligencia humana, la IA generativa también ha tenido un gran impacto en la educación superior, las bibliotecas académicas y la investigación académica. Por lo tanto, este artículo presenta algunos de los aspectos fundamentales de la ética de la IA que los bibliotecarios académicos deben comprender como necesarios para fundamentar sus decisiones individuales e institucionales sobre la adopción o el uso de la IA, la formación y las políticas, a fin de evitar perjuicios éticos, dada la naturaleza disruptiva de la IA como tecnología sin precedentes.
¿Qué es la ética de la IA?
La ética de la IA aborda las cuestiones éticas de la IA, incluidas qué normas morales se deben codificar en la IA para intentar que sea segura (alineación), qué constituye usos moralmente buenos y moralmente malos de la IA a nivel social (gobernanza, políticas, leyes) y a nivel individual, y las consecuencias éticas y el daño de la IA ya sea por su diseño o por cómo se utiliza. La ética de la IA aborda ampliamente:
Cuestiones éticas derivadas de las características de la IA (p. ej., problemas de privacidad, ya que la IA depende de datos personales para su entrenamiento).
Cuestiones éticas derivadas de cómo los humanos deciden usar la IA (p. ej., la definición de estándares éticos para un uso responsable de la IA frente a su uso para perjudicarse mutuamente).
El impacto social y ambiental de las cuestiones éticas de la IA (p. ej., el uso de la automatización de la IA para sustituir el trabajo humano). [2]
Dado que este breve artículo no puede abordar todas las cuestiones de la ética de la IA, hay que centrarse en el uso ético de la IA (no en su diseño ético) en función de cada categoría:
Las cuestiones éticas que surgen de la naturaleza de la IA como una forma de agencia sin precedentes. A saber, la erosión de los principios fundamentales de la dignidad humana debido al uso de la IA.
Los casos de uso ético de la IA (el bueno, el malo y el uso excesivo) para guiar su uso.
El daño social y ambiental causado por el uso excesivo irresponsable de la IA.
(A menos que se especifique lo contrario, «IA» se referirá a la IA generativa en la siguiente sección, dado que es la forma predominante de IA utilizada en las bibliotecas académicas).
La IA es agencia sin inteligencia.
La IA abarca una variedad de sistemas, algoritmos y modelos que destacan en la realización de tareas en áreas específicas con metas y objetivos claros. Sin embargo, la IA solo «imita el pensamiento y el razonamiento»; por lo tanto, no es inteligente. De hecho, la IA es simplemente una forma sin precedentes de agencia (la capacidad de actuar, interactuar con y manipular el mundo físico) que carece de inteligencia (la capacidad de pensar racionalmente).[4]
Por diseño, la IA es incapaz de comprender; no puede discernir el bien del mal, la verdad de la falsedad, la realidad de la invención, ni otros conceptos que requieren inteligencia. De hecho, la IA simplemente los ignora por completo. Debido a su propia naturaleza, la IA a menudo «alucina» o genera información falsa que presenta como un hecho. De igual manera, su capacidad para producir contenido de forma automática y rápida con una «personalización sin precedentes» y un «poder predictivo» nos hace sobreestimar considerablemente sus capacidades y pasar por alto sus defectos.
Agencia Humana, Inteligencia y Responsabilidad
La capacidad generalizada de la IA para moldear sutilmente nuestros pensamientos y acciones «predeterminados por algoritmos subyacentes» está oculta y está llevando a muchas personas a renunciar a parte de su autonomía humana sin darse cuenta. Por lo tanto, es esencial que protejamos nuestros principios fundamentales de dignidad humana: agencia: lo que podemos hacer; capacidad: lo que podemos lograr; autorrealización: en quiénes podemos convertirnos; y cuidado: cómo nos tratamos unos a otros (conexión) y a nuestro entorno. La erosión de estos principios no solo conduce a la desigualdad social y económica, sino que también amenaza con limitar aquello que nos hace humanos.
Desafortunadamente, esto ya ha sucedido, como lo demuestran las empresas con ánimo de lucro, atraídas por la «eficiencia» de la IA, que han optado por reemplazar los empleos de muchas personas con la automatización de la IA, devaluando así su inteligencia, experiencia, habilidades y creatividad, y provocando desempleo y subempleo. A nivel individual, considere cuánto se vinculan la identidad personal, la autoestima y las aspiraciones de vida con el trabajo, y cuán negativamente afecta esta valoración de la agencia artificial sobre la agencia humana a las personas a nivel personal, social y económico.
Liu, Guoying, y Shu Liu. 2026. “Chatbots for Reference Services in Academic Libraries: Applications and Trends.” The Journal of Academic Librarianship 52: 103197. https://doi.org/10.1016/j.acalib.2025.103197
El artículo analiza la adopción y el funcionamiento de los chatbots en los servicios de referencia de bibliotecas universitarias a nivel mundial, en un contexto de transformación digital y creciente incorporación de la inteligencia artificial en el ámbito bibliotecario. A través de un estudio comparativo, las autoras examinan tanto sistemas basados en reglas como chatbots impulsados por IA, con el objetivo de identificar tendencias, capacidades tecnológicas y prácticas éticas en su implementación.
La investigación se apoya en un diseño metodológico en dos fases. En primer lugar, se realiza un escaneo ambiental de 205 instituciones académicas de referencia —incluyendo universidades del ranking QS, instituciones chinas de “Doble Primera Clase”, bibliotecas canadienses de investigación y casos destacados en Estados Unidos—, de las cuales solo 31 contaban con chatbots funcionales y accesibles al público. En una segunda fase, estos chatbots fueron evaluados mediante consultas estandarizadas que permitieron analizar su rendimiento en servicios básicos, recuperación de información, recomendaciones complejas y experiencia de usuario.
Los resultados muestran una adopción global limitada de chatbots en bibliotecas universitarias(15 %), con notables diferencias regionales. Mientras que China continental presenta tasas de implantación significativamente más altas, la adopción en América del Norte sigue siendo baja, pese a la abundante literatura sobre casos piloto. La mayoría de los sistemas analizados son chatbots híbridos o basados en IA generativa, capaces de manejar consultas rutinarias con eficacia, aunque presentan dificultades en tareas más complejas como la recuperación semántica avanzada o la generación de recomendaciones contextualizadas.
El estudio también pone de relieve importantes carencias en materia de transparencia y ética. Solo una minoría de los chatbots informa explícitamente sobre políticas de privacidad o el uso de datos, lo que plantea riesgos para la confianza del usuario y la responsabilidad institucional. Las autoras concluyen que, aunque los chatbots ofrecen un notable potencial para ampliar y mejorar los servicios de referencia, su desarrollo futuro debe apoyarse en estándares compartidos, una mejor integración con los sistemas bibliotecarios y un compromiso más firme con los principios de transparencia, inclusión y gobernanza ética.
La apertura de la Metroteka en Varsovia, una biblioteca integrada dentro de una estación del metro, como una respuesta innovadora a la tendencia generalizada de que los viajeros usen sus teléfonos móviles para desplazarse por contenidos digitales mientras viajan.
La Metroteka es la primera biblioteca pública integrada dentro de una estación de metro en Varsovia, Polonia. Fue inaugurada el 4 de septiembre de 2025 en la estación Kondratowicza de la línea M2 del metro, en el distrito de Targówek, como parte de una iniciativa innovadora para acercar la lectura y la cultura a los viajeros y residentes de la ciudad.
En lugar de los habituales anuncios digitales y pantallas luminosas en las estaciones, Metroteka ofrece alrededor de 16 000 libros distribuidos en 150 m², con zonas de lectura separadas para adultos y niños, espacios comunes para trabajar o estudiar, y un área estilo cafetería con bebidas calientes. Este diseño pretende ofrecer una alternativa sensorial y cultural al uso de pantallas, invitando a los usuarios a sumergirse en la lectura durante sus desplazamientos cotidianos. Este proyecto surge de la colaboración entre la Biblioteca Pública de Targówek, el Consejo y la Junta del Distrito de Targówek y la Autoridad del Metro de Varsovia, con el objetivo de transformar un espacio de tránsito cotidiano en un entorno cultural accesible.
El proyecto no solo busca fomentar la lectura casual entre personas de todas las edades, sino también reconectar a la comunidad con la literatura en un contexto donde el hábito lector ha estado en declive, como reflejan las bajas tasas de lectura en Polonia en años recientes. Además, la biblioteca incorpora elementos únicos como un muro de jardín hidroponico con hierbas y flores que sirven tanto de elemento estético como de conversación sobre sostenibilidad ambiental. Con sistemas de autoservicio para tomar y devolver libros (incluyendo taquillas disponibles las 24 h), Metroteka está diseñada para integrarse de forma natural en la rutina diaria de los viajeros, eliminando la necesidad de planificar una visita a una biblioteca tradicional y acercando así los libros al ritmo de la vida urbana moderna
Donald Trump ha impulsado políticas favorables a las grandes empresas tecnológicas, particularmente en el contexto de la inteligencia artificial (IA) y los semiconductores.
En un contexto en que las políticas tecnológicas de Estados Unidos ocupan un papel central en la agenda política de 2025, el New York Times describe cómo la administración de Donald Trump ha implementado decisiones que favorecen ampliamente a las grandes empresas tecnológicas (Big Tech) en temas clave como inteligencia artificial (IA) y semiconductores. Aunque Trump llegó al poder con promesas de dinamizar la economía y restablecer la competitividad nacional, muchas de sus acciones han coincidido con las demandas y prioridades estratégicas de compañías como Nvidia, Google, Meta y otras, consolidando una alianza práctica entre el gobierno y el sector tecnológico que ha desbloqueado políticas regulatorias, cambios en comercio internacional y promoción de inversiones en infraestructura tecnológica.
Según la cobertura disponible, Trump ha eliminado o debilitado diversas restricciones a la exportación de chips semiconductores avanzados, como los fabricados por Nvidia, y ha promovido la expansión de la infraestructura tecnológica —incluidos centros de datos y producción de chips— con el argumento de mantener la competitividad estadounidense en la carrera global por la IA. Estos movimientos reflejan una clara alineación con las prioridades de Silicon Valley y otros gigantes tecnológicos, que han visto beneficios en la reducción de regulaciones y la apertura de mercados internacionales
Uno de los elementos más destacados de esta relación es la revocación o debilitación de restricciones que limitaban la exportación de chips avanzados y la regulación de tecnologías emergentes. La administración ha eliminado barreras regulatorias, acelerado la construcción de centros de datos y aprobado la venta de chips de IA más potentes en mercados sensibles, como China, medidas que muchos ejecutivos tecnológicos consideran esenciales para mantener la dominancia global de la industria estadounidense en IA y hardware. Esto se ha logrado tras esfuerzos coordinados entre líderes del sector y altos funcionarios de la Casa Blanca, que integran a la industria en posiciones de influencia técnica y política.
Además, el gobierno ha emitido órdenes ejecutivas y desarrollado un “AI Action Plan” nacional, orientado a impulsar la innovación de IA eliminando lo que Trump y sus asesores consideran barreras burocráticas y políticas que podrían frenar la competitividad de Estados Unidos frente a rivales como China. Estas políticas priorizan la expansión de la infraestructura tecnológica, la expansión de exportaciones y la coordinación federal única de normativas, reduciendo el papel de regulaciones estatales y enfocando el crecimiento en un marco de mercado libre que favorece a los grandes actores establecidos. Si bien estas medidas han sido aplaudidas por sectores empresariales como impulsores del crecimiento económico, también han generado críticas desde sectores que advierten sobre riesgos de falta de regulación, concentración de poder corporativo y posibles impactos negativos en la protección de derechos y seguridad pública.
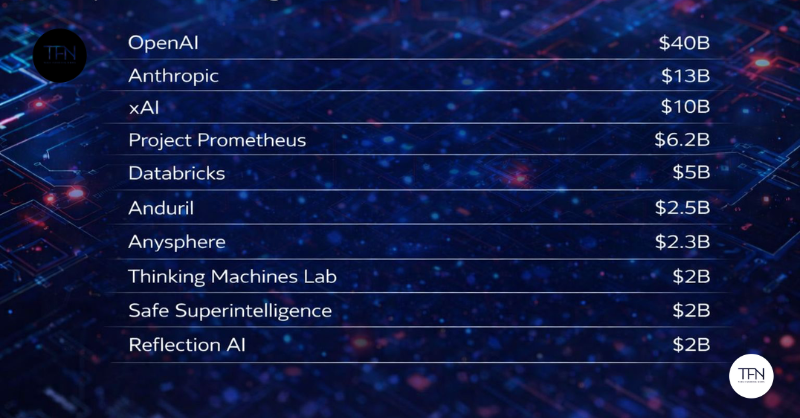
En 2025 el ecosistema de startups de inteligencia artificial (IA) en Estados Unidos ha alcanzado niveles excepcionales de financiación, concentrando enormes rondas de capital en un grupo reducido de empresas líderes.
Según TechFundingNews, las **10 mayores rondas de financiación de IA del año sumaron alrededor de 84 mil millones de dólares, evidenciando cómo los inversionistas están apostando decididamente por el desarrollo de modelos generativos, soluciones empresariales y plataformas de infraestructura de inteligencia artificial. Este patrón refleja una fuerte concentración de capital en proyectos que definen categorías tecnológicas emergentes y muestran gran potencial de crecimiento estratégico a largo plazo.
En el núcleo de estas inversiones está OpenAI, la organización detrás de ChatGPT y otros modelos de IA de propósito general, que lideró las rondas de 2025 con aproximadamente 40 mil millones de dólares recaudados en una sola ampliación de capital que sitúa su valoración posterior en unos 300 mil millones de dólares. Esta inyección de fondos —liderada por SoftBank con la participación de Microsoft, Coatue, Altimeter y Thrive— permitirá a OpenAI ampliar significativamente su infraestructura de cómputo, avanzar en investigación de punta y mejorar su capacidad para servir a más de 500 millones de usuarios semanales y a empresas que integran IA a gran escala.
De cerca le sigue Anthropic, fundada por los hermanos Daniela y Dario Amodei, que cerró una Serie F de 13 mil millones de dólares, elevando su valoración a aproximadamente 183 mil millones. Este capital reforzará la expansión internacional de sus productos de IA empresariales, profundizará la investigación en seguridad y ética de la IA y apoyará su crecimiento frente a competidores globales, consolidando su papel como uno de los laboratorios más influyentes en el espacio de la IA accesible y responsable.
Otra empresa que marcó tendencia es xAI, la compañía de inteligencia artificial fundada por Elon Musk. xAI recaudó más de 10 mil millones de dólares en financiación, alcanzando una valoración estimada en 200 mil millones de dólares, con el apoyo de inversores como Valor Capital, Qatar Investment Authority y Prince Al Waleed bin Talal. La financiación busca acelerar el despliegue de centros de datos propios y el desarrollo de modelos más eficientes (como Grok 4 Fast), que compitan directamente con los líderes del sector.
Además de estos gigantes, otras firmas tecnológicas especializadas también atrajeron importantes inversiones. Databricks obtuvo 5 mil millones para expandir su plataforma unificada de datos y análisis, mientras que empresas como Anduril (defensa autónoma), Anysphere (herramientas de productividad con IA), Thinking Machines Lab (fundada por ex-líderes de OpenAI), Safe Superintelligence (centrada en IA segura) y Reflection AI (automatización de código) recaudaron desde 2 hasta más de 2 mil millones cada una, reflejando la diversidad de aplicaciones y enfoques de la IA que están captando la atención de los fondos de capital riesgo.
En conjunto, estas rondas masivas muestran que la financiación de IA en 2025 no solo se trata de cantidades récord, sino de cómo se agrupan los recursos en empresas con grandes ambiciones tecnológicas y estratégicas. La concentración de capital en líderes de modelos generativos, infraestructura de datos y seguridad de IA sugiere que el mercado está apostando fuerte a que la próxima ola de innovación —y de cambio industrial— vendrá precisamente de estas plataformas dominantes.
El formato que ha hecho que los libros sean más accesibles gracias a sus bajos precios y su amplia disponibilidad desaparecerá prácticamente del panorama editorial en unas semanas.
La desaparición casi definitiva del formato mass market paperback en Estados Unidos, un tipo de libro de bolsillo barato que durante décadas fue fundamental para democratizar el acceso a la lectura. La decisión del principal distribuidor de este formato de abandonar su comercialización marca un punto de no retorno para un modelo editorial que ya llevaba años en declive.
La decisión tomada este invierno por ReaderLink de dejar de distribuir libros de bolsillo para el mercado de masas a finales de 2025 fue el último golpe para un formato que ha visto su popularidad decaer durante años. Según Circana BookScan, las ventas de unidades para el mercado de masas se desplomaron de 131 millones en 2004 a 21 millones en 2024, una caída de aproximadamente el 84%, y las ventas de este año hasta octubre fueron de aproximadamente 15 millones de unidades.
Durante gran parte del siglo XX, los mass market paperbacks fueron el formato más popular entre los lectores, gracias a su bajo coste, su amplia distribución en puntos de venta no tradicionales y su capacidad para mantener vivos títulos durante largos periodos. Permitieron que millones de personas accedieran a novelas y ensayos que, en tapa dura, resultaban inaccesibles para muchos bolsillos.
Sin embargo, el artículo explica que diversos factores han provocado su caída progresiva: el aumento de los costes de producción y distribución, los cambios en los hábitos de consumo, la reducción de espacios de venta físicos y la competencia de otros formatos como el trade paperback, el libro digital y el audiolibro. A ello se suma la transformación del sistema de distribución, cada vez menos compatible con productos de bajo margen económico.
El texto también subraya la dimensión cultural de esta desaparición. Aunque el mass market paperback ya no resulta viable desde el punto de vista comercial, su impacto histórico fue enorme, tanto en la expansión de la lectura como en la consolidación de autores y géneros populares. Su retirada simboliza un cambio profundo en la industria editorial y en la forma en que los lectores acceden hoy a los libros.
Más de 21 % de los vídeos recomendados a nuevos usuarios en YouTube son contenido de baja calidad generado por IA, conocido como AI slop, según un informe de Kapwing.
Un nuevo informe del sitio de análisis tecnológico Kapwing revela que más de uno de cada cinco videos que aparecen en las recomendaciones de YouTube para nuevos usuarios es “AI slop”, es decir, contenido generado por inteligencia artificial de baja calidad diseñado para obtener visualizaciones y suscripciones sin aportar valor real al espectador. Para medirlo, los investigadores crearon una cuenta nueva en la plataforma y analizaron los primeros 500 videos en el feed de YouTube Shorts, encontrando que alrededor del 21 % de ese contenido estaba compuesto por videos generados automáticamente, mientras que otro 33 % entraba en la categoría más amplia de “brainrot”, contenido trivial o repetitivo que persigue la atención del usuario.
El estudio también examinó 15 000 de los canales más populares en YouTube (los 100 principales en cada país) y determinó que 278 canales publican exclusivamente contenido AI slop. Estos canales, aunque de baja calidad en términos de aporte creativo o informativo, han acumulado decenas de miles de millones de visualizaciones y cientos de millones de suscriptores en total, generando ingresos estimados en decenas de millones de dólares al año.
Geográficamente, la presencia de “AI slop” es global: algunas regiones como España lideran el número de suscriptores de este tipo de canales, mientras que países como Corea del Sur o Pakistán registran cifras extraordinarias de visualizaciones de videos generados por IA. Estos hallazgos han encendido el debate sobre la calidad del contenido en plataformas dominadas por algoritmos de recomendación, así como las implicaciones para creadores humanos y la experiencia de los usuarios, especialmente cuando dichos sistemas priorizan volumen e interacción sobre contenido útil o auténtico.
Marta Mira Osuna, salmantina componente y líder del grupo HERSCHEL, dibuja el retrato de una creadora que ha sabido unir dos vocaciones aparentemente distantes: la biotecnología y la música. Salmantina afincada en Rennes, Marta explica cómo la banda —formada por tres amigas— se sostiene sobre una fuerte amistad y complicidad, algo que se traduce en una energía muy reconocible en directo y en una manera honesta de compartir escenario.
HERSCHEL bebe de referentes del indie rock internacional como Arctic Monkeys, Wolf Alice o The Black Keys, pero Marta subraya que la identidad del grupo surge de filtrar esas influencias a través de experiencias propias, sin perder autenticidad. En su caso, la música comenzó como un refugio personal y acabó convirtiéndose en un proyecto vital a partir de 2018, cuando se atrevió a tocar en público por primera vez en el paseo marítimo de Huelva, una experiencia fundacional que aún reconoce en la artista que es hoy.
Vivir en Rennes, ciudad con una escena musical muy activa, ha sido clave en su evolución. El ecosistema cultural bretón le ha aportado profesionalización, contacto con otras bandas y una concepción del directo como experiencia colectiva. Marta encuentra paralelismos entre el laboratorio y el escenario: método, constancia, curiosidad y trabajo en equipo, demostrando que ciencia y arte no son mundos tan alejados.
Su faceta compositiva se caracteriza por el multilingüismo: escribe en español, francés e inglés, eligiendo cada idioma según la emoción o la historia que quiere contar, lo que le permite matizar su voz creativa. Un ejemplo singular fue el proyecto musical inspirado en la saga literaria Aquelarre, escrita por sus hermanos, donde tuvo que traducir personajes y universos de ficción al lenguaje sonoro.
La entrevista también aborda su experiencia “al otro lado” del escenario, como presidenta de la asociación musical de la Universidad de Rennes, que le permitió comprender la logística y el esfuerzo que hay detrás de cada concierto. El reconocimiento del Trampolín Musical de Rennes supuso un impulso decisivo para HERSCHEL, validando el proyecto y abriéndole nuevas oportunidades.
En el momento actual la banda esta grabando de su primer disco «No Slow Release«. Un álbum refleja un punto de madurez personal y creativa, con canciones más definidas y una banda consciente de su identidad, lista para compartirla con el público.
Con motivo del V Encuentro Rock Reunion en Salamanca, Juan Márquez, bajista, cantante y líder histórico del grupo madrileño COZ, repasa una trayectoria fundamental para entender los orígenes del rock duro en español. Vinculado a la escena rock de Madrid desde comienzos de los años setenta, Márquez se convirtió en la figura central de COZ tras su formación en 1974, una de las bandas pioneras del género en nuestro país. Como voz principal, bajista y compositor de buena parte del repertorio más emblemático del grupo, Juan Márquez fue clave en el éxito de canciones que marcaron una época, como «Más sexy» o «Las chicas son guerreras», temas que otorgaron a COZ una gran popularidad a finales de los años setenta y comienzos de los ochenta.
Lejos de ser un proyecto del pasado, COZ continúa en activo bajo su liderazgo. Prueba de ello es el álbum La Suite Carmesí (2022), un trabajo que reafirma la vigencia de su propuesta y su compromiso con el rock duro en español, una música que sigue encontrando público y sentido décadas después de sus inicios.